Bahasa Inggris adalah bahasa Jermanik Barat yang muncul di kerajaan Anglo-Saxon Inggris dan menyebar ke apa yang kemudian menjadi Skotlandia tenggara di bawah pengaruh Anglikan abad pertengahan dari kerajaan Northumbria.
KONTEN ISI
1. Makna
2. Sejarah
3. Klasifikasi dan bahasa yang berhubungan
4. Pembagian Geografik
4.1. Bahasa Inggris sebagai bahasa dunia
4.2. Dialek dan varietas daerah
5. Fonologi
5.1. Huruf vokal
5.2. Huruf konsonan
6. Tata bahasa
7. Kosa kata
7.1. Jumlah kata dalam bahasa Inggris
7.2. Asal kata
7.2.1. Dari bahasa Prancis
7.2.1. Dari Norse lama
7.2.1. Dari bahasa Belanda dan Jerman Rendah
8. Sistem penulisan
8.1. Korespondensi huruf-suara konsonan dasar
8.2. Aksen penulisan
9. Penulisan formal bahasa Inggris
10. Versi dasar dan disederhanakan
Makna
Bahasa Inggris Modern, kadang-kadang digambarkan sebagai lingua franca global pertama, yaitu merupakan bahasa yang dominan atau dalam beberapa kasus bahkan bahasa internasional yang diperlukan dalam komunikasi, ilmu pengetahuan, teknologi informasi, bisnis, pelayaran, penerbangan, hiburan, radio dan diplomasi. Penyebarannya di luar Kepulauan Inggris dimulai seiring dengan pertumbuhan Kerajaan Inggris, dan pada akhir abad 19 jangkauannya benar-benar global. Setelah kolonisasi Inggris dari abad ke-16 sampai abad ke-19, bahasa Inggris menjadi bahasa yang dominan di Amerika Serikat, Kanada, Australia dan Selandia Baru. Pengaruh ekonomi dan budaya yang tumbuh dari AS dan statusnya sebagai negara adidaya global sejak Perang Dunia II telah secara signifikan mempercepat penyebaran bahasa Inggris di seluruh planet. Bahasa Inggris menggantikan bahasa Jerman sebagai bahasa yang dominan dari peraih ilmu pengetahuan Hadiah Nobel pada paruh kedua abad ke-20. Inggris setara dan mungkin telah melampaui bahasa Prancis sebagai bahasa diplomasi yang dominan selama paruh terakhir abad ke-19.
Pengetahuan bahasa Inggris telah menjadi kebutuhan di sejumlah bidang, pekerjaan dan profesi seperti kedokteran dan komputasi; sebagai akibatnya lebih dari satu miliar orang berbahasa Inggris untuk setidaknya pada tingkat dasar. Ini adalah salah satu dari enam bahasa resmi PBB.
Salah satu dampak dari pertumbuhan bahasa Inggris adalah pengurangan keanekaragaman linguistik asli di banyak bagian dunia. Pengaruhnya terus memainkan peran penting dalam atrisi bahasa. Sebaliknya, berbagai internal alami dari bahasa Inggris bersama dengan Creoles dan pidgins memiliki potensi untuk menghasilkan bahasa yang berbeda dari bahasa Inggris baru dari waktu ke waktu.
Sejarah
Bahasa Inggris adalah bahasa Jermanik Barat yang berasal dari dialek Anglo-Frisia dan Saxon Lama yang dibawa ke Inggris oleh pemukim Jermanik dari berbagai bagian yang sekarang disebut Jerman barat laut, Denmark dan Belanda. Hingga saat itu, di Inggris Roma, penduduk asli diasumsikan telah berbicara bahasa Celtic Brythonic bersama dengan pengaruh akrolektal Latin, dari pendudukan Romawi 400 tahun.
Salah satu suku Jermanik yang masuk adalah Angles, yang Bede diyakini telah dipindahkan seluruhnya ke Inggris. Nama 'England' (dari Engla Land, "Tanah Angles") dan English (Inggris Kuno Englisc) berasal dari nama suku ini-tapi Saxon, Jutes dan berbagai bangsa Jerman dari pantai Frisia, Lower Saxony, Jutland dan Selatan Swedia juga pindah ke Inggris di era ini.
Awalnya, Inggris Kuno adalah berbagai kelompok dialek yang mencerminkan asal-usul beragam kerajaan Anglo-Saxon dari Britania Raya tetapi salah satu dialek ini, Saxon Barat Akhir, akhirnya datang untuk mendominasi dan dalam hal ini puisi Beowulf ditulis.
Inggris Kuno kemudian ditransformasikan oleh dua gelombang invasi. Yang pertama adalah oleh pembicara dari cabang bahasa Jermanik Utara saat Halfdan Ragnarsson dan Ivar the Boneless mulai menaklukkan dan mengolonisasi dari bagian utara kepulauan Inggris pada abad ke-8 dan 9. Yang kedua adalah oleh penutur bahasa Roman, Norman Lama di abad ke-11 dengan penaklukan Norman dari Inggris.
Rabu, 23 November 2011
Jumat, 15 Juli 2011
BAHASA MANDARIN (官话)
Dalam linguistik Cina, bahasa Mandarin (Cina Sederhana: 官话; Cina Tradisional: 官話; Pinyin: Guānhuà; secara harfiah: "pidato pejabat") mengacu pada kelompok dialek Cina terkait yang digunakan di sebagian besar bagian utara dan barat daya Cina. Karena bahasa Mandarin terutama mencakup kelompok pidato yang ditemukan di utara, istilah "dialek utara" (Cina Sederhana: 北方话; Cina Tradisional: 北方話; Pinyin: Běifānghuà) juga menamakan kelompok bahasa ini secara informal. Ada variasi regional dalam pengucapan, kosa kata dan tata bahasa, seperti di Inggris, Skotlandia, Irlandia, Australia, Kanada, dan Amerika Serikat. Seorang pembicara berdialek Timur Laut dan pembicara berdialek Barat Daya hampir tidak dapat berkomunikasi kecuali melalui bahasa standar, terutama karena perbedaan dalam nada. Meskipun demikian, variasi dalam bahasa Mandarin tidak membandingkan dengan variasi yang jauh lebih besar yang ditemukan dalam beberapa varietas lain Cina dan ini diperkirakan karena penyebaran bahasa Mandarin yang relatif baru di seluruh Cina dikombinasikan dengan kemudahan perjalanan dan komunikasi dibandingkan dengan bagian selatan pegunungan Cina.
Ketika kelompok bahasa Mandarin diambil sebagai satu bahasa, seperti yang sering dilakukan dalam literatur akademis, ia memiliki lebih banyak penutur asli daripada bahasa lain, hampir 1 milyar orang. Bagi sebagian besar sejarah China, ibu kota sudah berada di dalam wilayah bahasa Mandarin yang membuat dialek ini sangat berpengaruh. Dialek Mandarin, khususnya dialek Beijing, membentuk dasar bahasa Cina Baku yang juga dikenal sebagai "bahasa Mandarin".
KONTEN ISI
1. Nama
2. Sejarah
2.1. Bahasa Mandarin Lama
2.2. Literatur Bahasa Daerah
2.3. Bahasa Cina Baku
3. Fonologi
3.1. Awal
3.2. Akhir
3.3. Nada
4. Tata Bahasa
4.1. Partikel Akhir Kalimat
4.2. Reduplikasi
5. Kosa Kata
Nama
Kata "Mandarin" (dari bahasa Portugis mandarim, dari bahasa Melayu [ˈməntəri], dari bahasa India mantri, dari bahasa Sanskerta mantrin yang semuanya berarti "menteri atau konselor") awalnya berarti seorang pejabat Kekaisaran Cina. Sebagai dialek rumah mereka yang bervariasi dan sering saling tidak dapat dimengerti, para pejabat ini berkomunikasi dengan menggunakan Koine didasarkan pada berbagai dialek bagian utara. Ketika misionaris Yesuit belajar bahasa standar di abad ke-16, mereka menyebutnya bahasa Mandarin, dari nama Cina-nya Guānhuà (官话/官话) "bahasa pejabat".
Dalam bahasa Indonesia sehari-hari, "Mandarin" mengacu pada bahasa Cina standar yang sering disebut Bahasa Cina. Bahasa Cina standar didasarkan pada dialek Mandarin tertentu yang diucapkan di Beijing dengan beberapa pengaruh leksikal dan sintaksis dari dialek Mandarin lainnya. Ini adalah bahasa lisan resmi dari Republik Rakyat Cina (RRC), bahasa resmi Republik Cina (RC/Taiwan), dan salah satu dari empat bahasa resmi Singapura. Bahasa ini juga berfungsi sebagai bahasa pengantar di RRC dan di Taiwan. Ini adalah salah satu dari enam bahasa resmi PBB, di bawah nama "Cina". Penutur Cina mengacu pada bahasa standar modern sebagai Pǔtōnghuà (di RRC), Guóyǔ (di Taiwan) atau Huáyǔ (di Singapura), tetapi tidak sebagai Guānhuà.
Artikel ini menggunakan istilah "Mandarin" dalam artian digunakan oleh ahli bahasa, mengacu pada berbagai kelompok dialek Mandarin yang diucapkan di utara dan barat daya Cina yang ahli bahasa Cina menyebutnya Guānhuà. Istilah alternatif Běifānghuà (Cina Sederhana: 北方话; Cina Tradisional: 北方話) atau dialek utara digunakan semakin jarang di kalangan ahli bahasa Cina. Dengan ekstensi, istilah "Mandarin Lama" digunakan oleh ahli bahasa untuk merujuk pada dialek utara yang tercatat dalam bahan-bahan dari dinasti Yuan.
Penutur asli yang bukan ahli bahasa akademis mungkin tidak mengenali bahwa variasi yang mereka bicarakan diklasifikasikan dalam linguistik sebagai anggota "Mandarin" (atau yang disebut "Dialek Utara") dalam arti luas. Dalam wacana sosial atau budaya Cina, tidak ada identitas "Mandarin" biasa yang didasarkan pada bahasa, melainkan terdapat identitas regional yang kuat yang berpusat pada dialek individu karena dari distribusi geografis yang luas dan keanekaragaman budaya dari penutur mereka.
Seperti halnya semua jenis lain dari bahasa Cina, ada sengketa yang signifikan, mengenai apakah bahasa Mandarin adalah bahasa atau dialek.
Sejarah
Varietas bahasa Cina saat ini dikembangkan dari cara-cara berbeda di mana dialek Cina Lama dan Cina Tengah berevolusi. Secara tradisional, tujuh kelompok utama dari dialek telah diakui. Selain dari Mandarin, enam lainnya adalah Cina Wu, Cina Hakka, Cina Min, Cina Xiang, Cina Yue dan Cina Gan. Baru-baru ini, kelompok yang lebih spesifik lainnya telah diakui.
Bahasa Mandarin Lama
Setelah runtuhnya dinasti Song Utara, China utara berada di bawah kendali Dinasti Jin (Jurchen) dan Dinasti Yuan (Mongol). Selama periode ini pidato umum baru dikembangkan, didasarkan pada dialek dari Dataran Cina Utara di sekitar ibukota, bahasa tersebut disebut sebagai bahasa Mandarin Lama. Genre baru sastra bahasa daerah didasarkan pada bahasa ini, termasuk bentuk-bentuk ayat, drama dan cerita.
Konvensi berima ayat baru dikodifikasikan dalam kamus sajak yang disebut Zhongyuan Yinyun (1324). Penyimpangan radikal dari tradisi tabel sajak yang telah berevolusi selama berabad-abad sebelumnya, kamus ini berisi banyak informasi tentang fonologi dari Mandarin lama. Sumber selanjutnya adalah naskah 'Phags-pa yang berdasarkan pada abjad Tibet yang digunakan untuk menulis beberapa bahasa dari kekaisaran Mongol termasuk Cina, dan Ziyun Menggu, kamus sajak berdasarkan' Phags-pa. Buku-buku sajak berbeda dalam beberapa rincian, tetapi secara keseluruhan menunjukkan banyak ciri-ciri dialek Mandarin modern, seperti pengurangan dan penghilangan konsonan berhenti terakhir dan reorganisasi nada Cina Tengah.
Di Cina Tengah, pemberhentian awal dan afrikat menunjukkan kontras tiga-arah antara tidak bersuara yang tidak diaspirasikan, tak bersuara yang diaspirasikan dan konsonan bersuara. Ada empat nada dengan nada yang keempat atau "nada masuk" terdiri dari suku kata yang berakhir dengan pemberhentian (-p,-t atau-k). Suku kata dengan huruf awal bersuara cenderung diucapkan dengan nada yang lebih rendah, dan oleh Dinasti Tang terakhir setiap nada telah dibagi menjadi dua daftar yang terkondisi oleh huruf awal. Ketika penyuaraan hilang dalam semua dialek kecuali kelompok Wu, perbedaan ini menjadi fonemik dan sistem inisial dan nada itu diatur kembali secara berbeda di masing-masing kelompok besar.
Zhongyuan Yinyun menunjukkan sistem khas empat nada bahasa Mandarin yang dihasilkan dari pemecahan nada "bahkan" dan hilangnya nada masuk, dengan suku kata yang didistribusikan di seluruh nada lain (meskipun asal mereka yang berbeda ditandai dalam kamus). Demikian pula pemberhentian bersuara dan afrikat telah menjadi aspirasi tidak bersuara dalam nada "bahkan" dan nonaspirasi tidak bersuara di tempat lain, perkembangan lain khas bahasa Mandarin. Namun bahasa itu masih memiliki -m akhir yang telah bergabung dengan -n dalam dialek modern dan frikatif bersuara awal. Hal ini juga mempertahankan perbedaan antara velar dan sibilan alveolar di lingkungan langit-langit, yang kemudian bergabung dalam dialek sebagian besar bahasa Mandarin untuk menghasilkan serangkaian palatal (diterjemahkan j-, q- dan x- dalam pinyin).
Literatur bahasa daerah tumbuh subur masa itu juga menunjukkan kosa kata khas Mandarin dan sintaksis, meskipun beberapa, seperti kata ganti orang ketiga tā (他), dapat ditelusuri kembali ke zaman Dinasti Tang.
Jumat, 08 Juli 2011
Ortografi Bahasa Ceko
Ortografi bahasa Ceko adalah sistem aturan untuk menulis yang benar dalam bahasa Ceko. Sistem ortografi bahasa Ceko adalah diakritik. Háček ditambahkan ke huruf Latin standar untuk mengekspresikan suara yang asing bagi bahasa Latin (namun beberapa digraf telah disimpan - ch, dž ). Aksen tirus digunakan untuk bunyi vokal panjang.
Ortografi Ceko dianggap sebagai model untuk semua bahasa Slavia lainnya yang menggunakan huruf Latin seperti Polandia; ortografi Slovenia dan Slovakia serta Abjad Latin Gaj didasarkan pada bahasa Ceko.
KONTEN ISI
1. Prinsip
1.1. K Versus G
1.2. I "Lembut" dan Y "Keras"
1.3. Huruf Ě
1.4. Huruf Ů
1.5. Perpaduan Penyuaraan
1.6. Perjanjian Antara Subjek dan Predikat
1.7. Tanda Baca
1.8. Huruf Kapital
2. Sejarah
Prinsip
Kita dapat menyimpulkan bahwa ortografi bahasa Ceko pada dasarnya adalah fonemik (bukan fonetik) karena sebuah grafem individual biasanya berhubungan dengan fonem individu (bukan suara). Namun, beberapa grafem dan kelompok huruf adalah sisa-sisa fonem sejarah yang digunakan di masa lalu tetapi sejak itu digabungkan dengan fonem lain. Beberapa perubahan dalam fonologi tersebut belum tercermin dalam ortografi tersebut.
K Versus G
penyuaraan sebuah konsonan bahasa Ceko menggabungkan dengan yang ada pada konsonan berikut ini, jika ada (spodoba znělosti). Namun, konsonan ditulis secara etimologis (bertentangan dengan beberapa ortografi Slavia lainnya). Untuk alasan historis, konsonan [g] ditulis k dalam kata-kata bahasa Ceko, seperti kde (dimana) atau kdo (siapa). Hal ini karena huruf g secara historis digunakan untuk konsonan [j].
Fonem Slavia asli /g/ berubah menjadi /h/ pada periode Ceko zaman dulu. Jadi, /g/ bukan fonem yang terpisah (dengan grafem yang sesuai) dengan kata asli dalam negeri; itu hanya terjadi dalam kata-kata asing (misalnya graf, gram, dll).
I "Lembut" dan Y "Keras"
Huruf i/í dan y/ý keduanya diucapkan [ɪ/iː]. Y pada awalnya diucapkan [ī] seperti dalam Bahasa Polandia atau bahasa Rusia kontemporer. Namun, pada abad ke-14, perbedaan dalam lafal baku menghilang (telah dipertahankan dalam beberapa dialek di Ostrava dan sekitarnya). Dalam kata asli domestik, "i" lembut ditulis hanya setelah konsonan "lembut" atau "ambigu", sedangkan y "keras" mengikuti konsonan "lembut" atau "ambigu".
Konsonan keras dan lembut dalam bahasa Ceko
 Suara [ɟɪ/ɟiː, cɪ/ciː, ɲɪ/ɲiː] ditulis di/dí, ti/tí dan ni/ní, bukan ďi/ďí, ťi/ťí and ňi/ňí, misalnya: dalam lafal bahasa Ceko čeština: [ˈt͡ʃɛʃcɪna]. Suara [dɪ/diː, tɪ/tiː, nɪ/niː] dilambangkan masing-masing dengan dy/dý, ty/tý, ny/ný.
Suara [ɟɪ/ɟiː, cɪ/ciː, ɲɪ/ɲiː] ditulis di/dí, ti/tí dan ni/ní, bukan ďi/ďí, ťi/ťí and ňi/ňí, misalnya: dalam lafal bahasa Ceko čeština: [ˈt͡ʃɛʃcɪna]. Suara [dɪ/diː, tɪ/tiː, nɪ/niː] dilambangkan masing-masing dengan dy/dý, ty/tý, ny/ný.
Dalam kata yang berasal dari luar negeri, di, ti, ni diucapkan [dɪ, tɪ, nɪ].
Konsonan ambigu dapat diikuti baik oleh i maupun y. Dalam beberapa kasus, mereka membedakan arti yang berbeda dari kata-kata, misalnya být (menjadi) versus bít (memukul), mýt (mencuci) versus mít (memiliki). Di sekolah murid-murid harus menghafal akar kata dan awalan dimana y tertulis; i ditulis dalam kasus lain.
Penulisan i atau y di akhir tergantung pada pola deklinasi.
Secara historis huruf c adalah keras, tapi ini berubah pada abad ke-19. Namun, dalam beberapa kata-kata, itu masih diikuti dengan huruf y: tác (baki) – tácy (baki (plural)).
Huruf Ě
Huruf ini tidak pernah dapat muncul di posisi awal, dan diucapkan sesuai dengan konsonan sebelumnya:
Huruf Ů
Ada dua cara dalam bahasa Ceko untuk menuliskan [uː] panjang: ú atau ů.
Secara historis, /ú/ panjang berubah menjadi diftong /ou/ [oʊ]. Pada tahun 1848 ou pada awal kata dasar diubah menjadi u dalam kata-kata seperti ouřad. Jadi, huruf u ditulis pada awal kata dan hanya kata dasarnya: úhel (sudut), trojúhelník (segitiga).
/ó/ [oː] panjang berubah menjadi diftong /uo/ [ʊo]. Huruf o pada bunyi rangkap itu kadang-kadang ditulis sebagai cincin di atas huruf u: ů, misalnya, kóň > kuoň > kůň (kuda). Kemudian, pengucapannya berubah menjadi [uː] tapi grafem /ů/ tetap. Hal tersebut serupa dengan ortografi bahasa Jerman yang mengubah ue menjadi ü. Ini tidak pernah terjadi pada awal kata-kata: dům (rumah), domů (rumah (home)).
Perpaduan Penyuaraan
Konsonan bersuara dapat diucapkan tanpa suara, dan konsonan tak bersuara menyuarakan masing-masing, sehingga kelompok konsonan seluruhnya sering diucapkan voiced resp. voiceless. Rekan-rekan voiced resp. voiceless tertulis dipelihara sesuai dengan etimologi kata, misalnya: odpadnout [ˈotpadnoʊ̯t] (memungkiri), -od- adalah sebuah prefiks.
Perjanjian Antara Subjek dan Predikat
Predikat harus selalu sesuai dengan subjek dalam kalimat - dalam jumlah dan orang (kata ganti pribadi), dan dengan partisipel masa lalu dan pasif juga dalam jenis kelamin. Prinsip tata bahasa mempengaruhi ortografi (lihat juga I "Lembut" dan Y "Keras") - itu sangatlah penting untuk pilihan yang benar dan penulisan akhiran jamak dari partisipel.
Contoh:
 Contoh yang disebutkan menunjukkan partisipel masa lalu (byl, byla ...) dan partisipel pasif (koupen, koupena ...). Penyesuaian dalam jenis kelamin berlaku pada konteks waktu lampau dan kalimat pasif, tidak dalam konteks waktu sekarang dan konteks waktu akan datang dalam kalimat aktif.
Contoh yang disebutkan menunjukkan partisipel masa lalu (byl, byla ...) dan partisipel pasif (koupen, koupena ...). Penyesuaian dalam jenis kelamin berlaku pada konteks waktu lampau dan kalimat pasif, tidak dalam konteks waktu sekarang dan konteks waktu akan datang dalam kalimat aktif.
Jika subjek kompleks adalah kombinasi kata benda dari jenis kelamin yang berbeda, jenis kelamin maskulin bernyawa adalah sebelum yang lainnya dan jenis kelamin maskulin mati dan feminin maskulin adalah sebelum jenis kelamin netral.
Contoh:
muži a ženy byli ― laki-laki dan wanita adalah (men and women were)
kočky a koťata byly ― kucing dan anak kucing adalah (cats and kittens were)
my jsme byli (my = kita (untuk laki-laki)) versus my jsme byly (my = kita (untuk perempuan))
Prioritas Jenis Kelamin:
maskulin bernyawa > maskulin tak bernyawa versus feminin > netral
Tanda Baca
Penggunaan titik (.), titik dua (:), titik koma (;), tanda tanya (?) dan tanda seru (!) mirip dengan penggunaannya dalam bahasa-bahasa Eropa lainnya. Tanda titik ditempatkan setelah angka jika adalah singkatan dari angka ordinal, misalnya: 1. den (= první den) – hari pertama.
Tanda koma digunakan untuk memisahkan bagian-bagian individu dalam kalimat kompleks-majemuk, senarai, bagian terpencil kalimat, dll. Penggunaannya dalam bahasa Ceko berbeda dari bahasa Indonesia. Misalnya, klausa terikat harus selalu dipisahkan dari prinsip klausa bebasnya. Sebuah tanda koma tidak pernah ditempatkan sebelum a (dan), i (maupun), ani (atau/nor) dan nebo (atau/or) ketika mereka menghubungkan bagian-bagian kalimat atau klausa dalam konjungsi kata sambung yg menggabungkan. Ini harus ditempatkan di konjungsi nonkopulatif (konsekuensi, penekanan, pengecualian, dsb.). Namun, sebuah tanda koma dapat terjadi di depan kata a (dan) jika yang sebelumnya adalah bagian dari cakupan batasan koma: Jakub, můj mladší bratr, a jeho učitel Filip byli příliš zabráni do rozhovoru. (Yakub, adikku dan gurunya, Filip, terlalu asik mengobrol.). Sebuah tanda koma juga memisahkan subordinat konjungsi yang diselipkan oleh konjungsi gabungan a proto (oleh karena itu/sehingga) dan a tak (dan sebagainya).
Contoh:
Apostrof jarang digunakan dalam bahasa Ceko. Mereka dapat melambangkan suara hilang dalam pidato tidak baku, tapi itu bersifat opsional, misalnya řek' atau řek (= řekl, dia berkata).
Huruf Kapital
Kata pertama dari setiap kalimat dan semua nama yang benar menggunakan huruf besar. Kasus-kasus tertentu yaitu:
Sejarah
Ada lima periode dalam perkembangan sistem ortografi bahasa Ceko:
Ortografi Ceko dianggap sebagai model untuk semua bahasa Slavia lainnya yang menggunakan huruf Latin seperti Polandia; ortografi Slovenia dan Slovakia serta Abjad Latin Gaj didasarkan pada bahasa Ceko.
KONTEN ISI
1. Prinsip
1.1. K Versus G
1.2. I "Lembut" dan Y "Keras"
1.3. Huruf Ě
1.4. Huruf Ů
1.5. Perpaduan Penyuaraan
1.6. Perjanjian Antara Subjek dan Predikat
1.7. Tanda Baca
1.8. Huruf Kapital
2. Sejarah
Prinsip
Kita dapat menyimpulkan bahwa ortografi bahasa Ceko pada dasarnya adalah fonemik (bukan fonetik) karena sebuah grafem individual biasanya berhubungan dengan fonem individu (bukan suara). Namun, beberapa grafem dan kelompok huruf adalah sisa-sisa fonem sejarah yang digunakan di masa lalu tetapi sejak itu digabungkan dengan fonem lain. Beberapa perubahan dalam fonologi tersebut belum tercermin dalam ortografi tersebut.
K Versus G
penyuaraan sebuah konsonan bahasa Ceko menggabungkan dengan yang ada pada konsonan berikut ini, jika ada (spodoba znělosti). Namun, konsonan ditulis secara etimologis (bertentangan dengan beberapa ortografi Slavia lainnya). Untuk alasan historis, konsonan [g] ditulis k dalam kata-kata bahasa Ceko, seperti kde (dimana) atau kdo (siapa). Hal ini karena huruf g secara historis digunakan untuk konsonan [j].
Fonem Slavia asli /g/ berubah menjadi /h/ pada periode Ceko zaman dulu. Jadi, /g/ bukan fonem yang terpisah (dengan grafem yang sesuai) dengan kata asli dalam negeri; itu hanya terjadi dalam kata-kata asing (misalnya graf, gram, dll).
I "Lembut" dan Y "Keras"
Huruf i/í dan y/ý keduanya diucapkan [ɪ/iː]. Y pada awalnya diucapkan [ī] seperti dalam Bahasa Polandia atau bahasa Rusia kontemporer. Namun, pada abad ke-14, perbedaan dalam lafal baku menghilang (telah dipertahankan dalam beberapa dialek di Ostrava dan sekitarnya). Dalam kata asli domestik, "i" lembut ditulis hanya setelah konsonan "lembut" atau "ambigu", sedangkan y "keras" mengikuti konsonan "lembut" atau "ambigu".
Konsonan keras dan lembut dalam bahasa Ceko
 Suara [ɟɪ/ɟiː, cɪ/ciː, ɲɪ/ɲiː] ditulis di/dí, ti/tí dan ni/ní, bukan ďi/ďí, ťi/ťí and ňi/ňí, misalnya: dalam lafal bahasa Ceko čeština: [ˈt͡ʃɛʃcɪna]. Suara [dɪ/diː, tɪ/tiː, nɪ/niː] dilambangkan masing-masing dengan dy/dý, ty/tý, ny/ný.
Suara [ɟɪ/ɟiː, cɪ/ciː, ɲɪ/ɲiː] ditulis di/dí, ti/tí dan ni/ní, bukan ďi/ďí, ťi/ťí and ňi/ňí, misalnya: dalam lafal bahasa Ceko čeština: [ˈt͡ʃɛʃcɪna]. Suara [dɪ/diː, tɪ/tiː, nɪ/niː] dilambangkan masing-masing dengan dy/dý, ty/tý, ny/ný.Dalam kata yang berasal dari luar negeri, di, ti, ni diucapkan [dɪ, tɪ, nɪ].
Konsonan ambigu dapat diikuti baik oleh i maupun y. Dalam beberapa kasus, mereka membedakan arti yang berbeda dari kata-kata, misalnya být (menjadi) versus bít (memukul), mýt (mencuci) versus mít (memiliki). Di sekolah murid-murid harus menghafal akar kata dan awalan dimana y tertulis; i ditulis dalam kasus lain.
Penulisan i atau y di akhir tergantung pada pola deklinasi.
Secara historis huruf c adalah keras, tapi ini berubah pada abad ke-19. Namun, dalam beberapa kata-kata, itu masih diikuti dengan huruf y: tác (baki) – tácy (baki (plural)).
Huruf Ě
Huruf ini tidak pernah dapat muncul di posisi awal, dan diucapkan sesuai dengan konsonan sebelumnya:
- [ɟɛ, cɛ, ɲɛ] ditulis dě, tě, ně, bukan ďe, ťe, ňe (mirip dengan di, ti, ni).
- Bě, pě, vě, fě ditulis bukan bje, pje, vje, fje. Tapi dalam beberapa kata (vjezd, pintu masuk, objem, volume), bje, vje ditulis karena –je– didahului oleh awalan v- atau ob- dalam kasus tersebut.
- [mɲɛ] ditulis mě, bukan mňe, kecuali untuk alasan-alasan etimologis dalam beberapa kata (jemný, halus, jemně, secara halus).
- Bě, pě, vě, fě ditulis bukan bje, pje, vje, fje. Tapi dalam beberapa kata (vjezd, pintu masuk, objem, volume), bje, vje ditulis karena –je– didahului oleh awalan v- atau ob- dalam kasus tersebut.
Huruf Ů
Ada dua cara dalam bahasa Ceko untuk menuliskan [uː] panjang: ú atau ů.
Secara historis, /ú/ panjang berubah menjadi diftong /ou/ [oʊ]. Pada tahun 1848 ou pada awal kata dasar diubah menjadi u dalam kata-kata seperti ouřad. Jadi, huruf u ditulis pada awal kata dan hanya kata dasarnya: úhel (sudut), trojúhelník (segitiga).
/ó/ [oː] panjang berubah menjadi diftong /uo/ [ʊo]. Huruf o pada bunyi rangkap itu kadang-kadang ditulis sebagai cincin di atas huruf u: ů, misalnya, kóň > kuoň > kůň (kuda). Kemudian, pengucapannya berubah menjadi [uː] tapi grafem /ů/ tetap. Hal tersebut serupa dengan ortografi bahasa Jerman yang mengubah ue menjadi ü. Ini tidak pernah terjadi pada awal kata-kata: dům (rumah), domů (rumah (home)).
Perpaduan Penyuaraan
Konsonan bersuara dapat diucapkan tanpa suara, dan konsonan tak bersuara menyuarakan masing-masing, sehingga kelompok konsonan seluruhnya sering diucapkan voiced resp. voiceless. Rekan-rekan voiced resp. voiceless tertulis dipelihara sesuai dengan etimologi kata, misalnya: odpadnout [ˈotpadnoʊ̯t] (memungkiri), -od- adalah sebuah prefiks.
Perjanjian Antara Subjek dan Predikat
Predikat harus selalu sesuai dengan subjek dalam kalimat - dalam jumlah dan orang (kata ganti pribadi), dan dengan partisipel masa lalu dan pasif juga dalam jenis kelamin. Prinsip tata bahasa mempengaruhi ortografi (lihat juga I "Lembut" dan Y "Keras") - itu sangatlah penting untuk pilihan yang benar dan penulisan akhiran jamak dari partisipel.
Contoh:
 Contoh yang disebutkan menunjukkan partisipel masa lalu (byl, byla ...) dan partisipel pasif (koupen, koupena ...). Penyesuaian dalam jenis kelamin berlaku pada konteks waktu lampau dan kalimat pasif, tidak dalam konteks waktu sekarang dan konteks waktu akan datang dalam kalimat aktif.
Contoh yang disebutkan menunjukkan partisipel masa lalu (byl, byla ...) dan partisipel pasif (koupen, koupena ...). Penyesuaian dalam jenis kelamin berlaku pada konteks waktu lampau dan kalimat pasif, tidak dalam konteks waktu sekarang dan konteks waktu akan datang dalam kalimat aktif.Jika subjek kompleks adalah kombinasi kata benda dari jenis kelamin yang berbeda, jenis kelamin maskulin bernyawa adalah sebelum yang lainnya dan jenis kelamin maskulin mati dan feminin maskulin adalah sebelum jenis kelamin netral.
Contoh:
muži a ženy byli ― laki-laki dan wanita adalah (men and women were)
kočky a koťata byly ― kucing dan anak kucing adalah (cats and kittens were)
my jsme byli (my = kita (untuk laki-laki)) versus my jsme byly (my = kita (untuk perempuan))
Prioritas Jenis Kelamin:
maskulin bernyawa > maskulin tak bernyawa versus feminin > netral
Tanda Baca
Penggunaan titik (.), titik dua (:), titik koma (;), tanda tanya (?) dan tanda seru (!) mirip dengan penggunaannya dalam bahasa-bahasa Eropa lainnya. Tanda titik ditempatkan setelah angka jika adalah singkatan dari angka ordinal, misalnya: 1. den (= první den) – hari pertama.
Tanda koma digunakan untuk memisahkan bagian-bagian individu dalam kalimat kompleks-majemuk, senarai, bagian terpencil kalimat, dll. Penggunaannya dalam bahasa Ceko berbeda dari bahasa Indonesia. Misalnya, klausa terikat harus selalu dipisahkan dari prinsip klausa bebasnya. Sebuah tanda koma tidak pernah ditempatkan sebelum a (dan), i (maupun), ani (atau/nor) dan nebo (atau/or) ketika mereka menghubungkan bagian-bagian kalimat atau klausa dalam konjungsi kata sambung yg menggabungkan. Ini harus ditempatkan di konjungsi nonkopulatif (konsekuensi, penekanan, pengecualian, dsb.). Namun, sebuah tanda koma dapat terjadi di depan kata a (dan) jika yang sebelumnya adalah bagian dari cakupan batasan koma: Jakub, můj mladší bratr, a jeho učitel Filip byli příliš zabráni do rozhovoru. (Yakub, adikku dan gurunya, Filip, terlalu asik mengobrol.). Sebuah tanda koma juga memisahkan subordinat konjungsi yang diselipkan oleh konjungsi gabungan a proto (oleh karena itu/sehingga) dan a tak (dan sebagainya).
Contoh:
- otec a matka – ayah dan ibu, otec nebo matka – ayah atau ibu (hubungan koordinasi - tidak ada koma)
- Je to pravda, nebo ne? – Ini benar atau tidak? (pengecualian)
- Pršelo, a proto nikdo nepřišel. – Saat itu sedang hujan, sehingga tidak ada seorang pun yang datang. (konsekuensi/akibat)
- Já vím, kdo to je. – Aku tahu siapa dia. Myslím, že se mýlíte. – Aku pikir kamu salah. (hubungan subordinasi)
- Jak se máš, Anno? – Apa kabar, Ana? (menunjukkan seseorang)
- Karel IV., římský císař a český král, založil hrad Karlštejn. – Charles IV., Kaisar Romawi dan raja Bohemia mendirikan kastel Karlštejn. (cakupan batasan koma)
- Je to pravda, nebo ne? – Ini benar atau tidak? (pengecualian)
- Petr řekl: „Přijdu zítra.“ – Peter berkata, "Aku akan datang besok."
Apostrof jarang digunakan dalam bahasa Ceko. Mereka dapat melambangkan suara hilang dalam pidato tidak baku, tapi itu bersifat opsional, misalnya řek' atau řek (= řekl, dia berkata).
Huruf Kapital
Kata pertama dari setiap kalimat dan semua nama yang benar menggunakan huruf besar. Kasus-kasus tertentu yaitu:
- Ungkapan rasa hormat - opsional: Ty (Anda (tunggal)), Tvůj (milik Anda (tunggal)), Vy (Anda (jamak)), Váš (milik Anda (jamak)), Bůh (Tuhan), Mistr (Tuan), dll.
- Judul – Huruf pertama pada kata pertama menggunakan huruf besar.
- Perkotaan dan pedesaan - Semua kata menggunakan huruf besar, kecuali untuk preposisi: Nové Město nad Metují - (New-Town-upon-Metuje).
- Nama geografis atau daerah - Huruf pertama menggunakan huruf besar, nama-nama umum sebagai ulice (jalan), náměstí (alun-alun/plaza) atau moře (laut) tidak menggunakan huruf besar: ulice Svornosti (Jalan Svornosti), Václavské náměstí (Plaza Wenceslas), Severní moře (Laut Utara). Sejak tahun 1993, preposisi awal dan kata berikutnya yang pertama menggunakan huruf besar: lékárna U Černého orla (Apotek Elang Hitam).
- Nama resmi lembaga pemerintahan - huruf pertama menggunakan huruf besar: Městský úřad v Kolíně (Kantor Kotamadya di Kolonye) versus městský úřad (Kantor Kotamadya).
- Nama bangsa dan kata benda kebangsaan menggunakan huruf besar: Anglie (Inggris), Angličan (orang Inggris), Německo (Jerman), Němec (orang Jerman). Kata sifat yang berasal dari nama-nama geografis dan nama-nama negara, seperti anglický (Inggris - adjektiva), pražský (Praha - adjektiva, misalnya: pražské metro - kereta api bawah tanah Praha) tidak menggunakan huruf besar. Nama-nama bahasa tidak menggunakan huruf besar: angličtina (bahasa Inggris), čeština (bahasa Ceko).
- Kata sifat kepunyaan yang berasal dari nama orang menggunakan huruf besar: Pavlův dům (rumah milik Paul).
- Judul – Huruf pertama pada kata pertama menggunakan huruf besar.
Sejarah
Ada lima periode dalam perkembangan sistem ortografi bahasa Ceko:
- Ortografi primitif. Untuk menulis suara yang asing ke abjad Latin, huruf dengan bunyi yang serupa digunakan. Catatan tertulis tertua yang dikenal dalam bahasa Ceko berasal dari abad ke-11. Sastra ditulis terutama dalam bahasa Latin pada periode ini.
- Ortografi digraf. Berbagai digraf digunakan untuk suara non-Latin. Sistem ini tidak konsisten dan juga tidak membedakan vokal panjang dan pendek.
- Ortografi diakritik oleh Jan Hus. Menggunakan diakritik untuk vokal panjang (tirus, "čárka" dalam bahasa Ceko) dan konsonan "lembut" ("punctus rotundus", titik di atas huruf) diusulkan untuk pertama kalinya dalam "De orthographia Bohemica" sekitar tahun 1406. Diakritik menggantikan digraf hampir seluruhnya. Ia juga menyarankan bahwa dialek Praha harus menjadi standar untuk bahasa Ceko. Jan Hus dianggap sebagai penulis dari pekerjaan itu, tetapi ada beberapa ketidakpastian tentang hal ini.
- Ortografi Brethren/Saudara seiman. Alkitab dari Kralice (1579-1593), terjemahan Ceko lengkap pertama dari Alkitab dari bahasa asli oleh Brethren Ceko menjadi model untuk bentuk sastra bahasa. Punctus rotundus (titik di atas huruf) digantikan oleh
- Ortografi digraf. Berbagai digraf digunakan untuk suara non-Latin. Sistem ini tidak konsisten dan juga tidak membedakan vokal panjang dan pendek.
Selasa, 05 Juli 2011
BAHASA CEKO
Bahasa Ceko (Bahasa Ceko: čeština, pengucapan: ˈt͡ʃɛʃcɪna) adalah bahasa Slavia barat dengan jumlah penutur sekitar 12 juta penutur asli. Bahasa Ceko adalah bahasa mayoritas di Negara Republik Ceko dan diucapkan oleh orang Ceko di seluruh dunia. Bahasa ini dikenal sebagai Bohemian dalam bahasa Inggris sampai akhir abad ke-19. Bahasa Ceko mirip dengan bahasa Slowakia dan pada tingkat lebih rendah mirip dengan bahasa Polandia dan Serbia.
KONTEN ISI
1. Nama
2. Fonologi
2.1. Huruf Vokal
2.2. Contoh Teks
2.3. Diftong
2.4. Konsonan
2.5. Penekanan
3. Sintaksis dan Morfologi
3.1. Susunan Kata
3.2. Jenis Kata
3.3. Dialek
3.4. Deklinasi
3.4.1. Preposisi dengan Kasus-Kasus Tertentu
3.4.2. Perhitungan dan Deklinasi
3.4.3. Jenis Kelamin
3.5. Bentuk Kata Kerja
4. Alfabet Bahasa Ceko
Nama
Nama "čeština", Ceko, berasal dari suku Slavia dari Ceko ("Čech", jamaknya "Češi" or "Čechové" (archaic)) yang menghuni Bohemia Tengah dan suku-suku Slavia tetangga bersatu di bawah pemerintahan dinasti Premyslid ("Přemyslovci"). Menurut legenda, bahasa Ceko berasal dari nenek moyang Čech, yang membawa suku orang Ceko ke dalam tanahnya. Nama varian bahasa Inggris "Bohemia" digunakan sampai akhir abad ke-19 yang mencerminkan nama bahasa Inggris asli dari negara Ceko yang berasal dari suku Celtic Boii yang mendiami wilayah itu sejak abad ke-4 SM.
Fonologi
Fonologi bahasa Ceko mungkin tampak tidak menarik bagi pembicara bahasa Inggris karena beberapa kata-kata tidak memiliki huruf hidup: zmrzl (padat beku), ztvrdl (mengeras), scvrkl (menyusut), čtvrthrst (seperempat genggaman), blb (bodoh), vlk (serigala) , atau smrt (kematian). Contoh populer dari hal tersebut adalah ungkapan ""strč prst skrz krk" yang berarti "tancapkan jari melalui tenggorokanmu" atau ungkapan "Smrž pln skvrn zvlhl z mlh." yang berarti "Morel penuh bintik-bintik yang dibasahi oleh kabut". Konsonan l dan r dapat berfungsi sebagai inti dari suku kata dalam bahasa Ceko karena mereka adalah konsonan sonoran. Fenomena yang sama juga terjadi dalam bahasa Inggris Amerika, di mana suku kata berkurang pada ujung "butter" dan "bottle" yang diucapkan [bʌɾ.ɹ] dan [bɒɾ.l], dengan suku kata konsonan sebagai inti suku kata. Bahasa Ceko juga memiliki fitur konsonan ř, fonem yang dikatakan unik untuk bahasa Ceko.
Huruf Vokal
Terdapat 10 huruf vokal dalam bahasa Ceko yang dianggap sebagai fonem individual. Ada 5 vokal pendek dan 5 vokal panjang.
Vokal panjang ditandai dengan aksen tajam di atas huruf atau tanda cincin di atas huruf.
/ iː / diwakili oleh huruf í dan ý
/ uː / diwakili oleh huruf ú dan ů
/ ɛː / diwakili oleh huruf é
/ aː / diwakili oleh huruf á
/ oː / diwakili oleh huruf ó
Vokal pendek
/ɪ/ diwakili oleh huruf i dan y
/u/ diwakili oleh huruf u
/ɛ/ diwakili oleh huruf e dan e
/a/ diwakili oleh huruf a
/o/ diwakili oleh huruf o
Contoh Teks
Bahasa Ceko: Všichni lidé se rodí svobodní a sobě rovní co do důstojnosti a práv. Jsou nadáni rozumem a svědomím a mají spolu jednat v duchu bratrství.
Bahasa Indonesia: Semua manusia dilahirkan bebas dan sama dalam martabat dan hak. Mereka dibekali dengan akal dan hati nurani dan harus bertindak dalam semangat persaudaraan.
Perhatikan bahwa ě bukan vokal terpisah. Sejalan dengan y, ý dan ů, itu adalah grafem yang dipelihara untuk alasan historis (lihat Ortografi Bahasa Ceko). ó hanya ada di kata-kata pinjaman.
Diftong
Ada tiga diftong dalam bahasa Ceko:
/aʊ̯/ diwakili oleh au (hampir seluruhnya dalam kata-kata asal luar negeri)
/eʊ̯/ diwakili oleh eu (dalam kata asal luar negeri saja)
/oʊ̯/ diwakili oleh ou
Ketika kelompok-kelompok ini datang bersama-sama pada batas morfem, mereka tidak membentuk diftong dalam standar bahasa Ceko, misalnya naučit, neučit, poučit ([-au-, -eu-, -ou-] or [-aʔu-, -eʔu-, -oʔu-]). Dalam kata asli bahasa Ceko, hanya ou yang ada sebagai diftong. Kelompok huruf hidup ia, ie, ii, io, dan iu dalam kata asing juga tidak dianggap sebagai diftong; mereka juga dapat diucapkan dengan /j/ antara huruf vokal [ɪja, ɪjɛ, ɪjɪ, ɪjo, ɪju].
Konsonan

Konsonan di dalam tanda kurung dianggap sebagai alofon dari konsonan lain:
[ŋ] adalah alofon dari /n/ ketika sebelumnya konsonan velar (/k/ dan /ɡ/).
[g] adalah alofon bersuara dari /k/ ketika mendahului konsonan disuarakan, kecuali dalam kata-kata
pinjaman.
[dz͡] adalah alofon dari /ts͡/ ketika mendahului konsonan bersuara.
Perhentian glotal (ʔ) yang muncul sebagai pemisah antara dua vokal atau kata awalnya sebelum vokal tidak dianggap sebagai fonem yang terpisah atau alofon dari satu.
/ʃ/ diwakili oleh huruf š
/ʒ/ diwakili oleh huruf ž
/ɲ/ diwakili oleh huruf ň
/c/ diwakili oleh huruf ť
/ɟ/ diwakili oleh huruf ď
/ɦ/ diwakili oleh huruf h
/x/ diwakili oleh digraf ch
/ts/ diwakili oleh huruf c
/tʃ/ diwakili oleh huruf č
/dʒ/ diwakili oleh digraf dž
/r̝/ diwakili oleh huruf ř
Konsonan lain diwakili oleh karakter yang sama (huruf) seperti dalam IPA/AFI.
Penekanan
Penekanan utama selalu tetap pada suku kata pertama dari unit yang ditekankan yang biasanya identik dengan kata. Pengecualiannya adalah:
Penekanan dalam bahasa Ceko menunjukkan batas-batas antara kata-kata, tetapi tidak membedakan makna kata. Hal ini juga tidak memiliki pengaruh pada kualitas atau kuantitas huruf vokal. Huruf vokal tidak berkurang dalam suku kata tanpa tekanan dan kedua vokal panjang dan pendek dapat terjadi baik dalam suku kata bertekanan atau tanpa tekanan.
Sintaksis dan Morfologi
Seperti dalam bahasa Slavia kebanyakan, banyak kata (terutama kata benda, kata kerja dan kata sifat) memiliki banyak bentuk (infleksi). Dalam hal ini, bahasa Ceko dan bahasa-bahasa Slavia lebih dekat dengan asal Indo-Eropa mereka daripada bahasa lain dalam keluarga yang sama yang telah kehilangan banyak infleksi. Selain itu, dalam bahasa Ceko, aturan morfologi sangatlah tidak teratur dan banyak variasi bentuk resmi, sehari-hari dan kadang-kadang semi-resmi.
Susunan Kata
Susunan kata dalam bahasa Ceko berfungsi hampir sama dengan penekanan kalimat dan artikel dalam bahasa Inggris. Seringkali semua permutasi dari kata dalam klausa adalah mungkin. Sementara sebagian besar permutasi berbagi makna yang sama, mereka berbeda dalam artikulasi topik-fokus.
Misalnya: Češi udělali revoluci (Orang-orang Ceko membuat revolusi), Revoluci udělali Češi (Ini adalah orang-orang Ceko yang membuat revolusi) dan Češi revoluci udělali (Orang-orang Ceko memang membuat revolusi). Biasanya susunan kata mengikuti pola berdasarkan pentingnya kata-kata dinyatakan - dari paling tidak penting sampai yang paling penting. Dengan mengatakan Revoluci udělali Češi pembicara menekankan bahwa itu adalah orang Ceko dan bukan misalnya Jerman atau Slowakia yang membuat revolusi. Dengan mengatakan Češi revoluci udělali, pembicara menekankan bahwa revolusi telah dilakukan, dan yang menjadi jauh lebih penting dari itu adalah orang Ceko yang berdiri di belakangnya. Dikombinasikan dengan melodi suara kalimat yang adalah sama untuk setiap jenis kalimat - pengumuman, pertanyaan dan keharusan dan yang menandai akhir setiap kalimat, orang dapat dengan mudah memahami konteks penting dari apa yang dikatakan dengan hanya mendengarkan kata akhir dalam setiap kalimat.
Jenis Kata
Dialek
Di Republik Ceko, dua varian yang berbeda atau interdialek dari pengucapan bahasa Ceko dapat ditemukan, keduanya lebih terkait atau kurang untuk wilayah geografis di dalam negeri. Yang pertama dan paling banyak digunakan adalah "bahasa Ceko Umum", diucapkan terutama di Bohemia. Ia memiliki beberapa perbedaan tata bahasa dari bahasa Ceko "baku" disertai dengan beberapa perbedaan dalam pengucapan. Perubahan pengucapan paling umum adalah -y menjadi-e dalam beberapa keadaan, -é menjadi-ý- dalam beberapa keadaan (-ej- di lainnya). Selain itu, deklinasi kata benda akan berubah, terutama kasus instrumental. Daripada memiliki berbagai akhiran (tergantung pada jenis kelamin) dalam instrumental, Bohemia hanya akan menempatkan -ama atau -ma pada akhir dari semua deklinasi instrumental yang jamak. Saat ini, bentuk-bentuk ini sangat umum di seluruh Republik Ceko, termasuk Moravia dan Silesia. Selain itu, pengucapan berubah sedikit, seperti Bohemia cenderung memiliki huruf vokal lebih terbuka daripada Moravia. Hal ini konon sangat lazim di kalangan orang-orang dari Praha.
Varian utama kedua diucapkan di Moravia dan Silesia. Saat ini. varian tersebut sangat dekat dengan bentuk Bohemia Ceko yang umum. Varian ini memiliki beberapa kata yang berbeda dari kesetaraan bahasa Ceko yang baku. Sebagai contoh dalam dialek lisan di Brno, tramvaj (trem) adalah šalina (berasal dari bahasa Jerman "ElektriSCHELINIE"). Tidak seperti di Bohemia, Moravia dan Silesia cenderung memiliki dialek yang lebih lokal yang memvariasikan dari tempat ke tempat, namun seperti halnya di Bohemia, sebagian besar telah sudah sangat dipengaruhi dan sebagian besar digantikan oleh bahasa Ceko yang umum. Bentuk lisan sehari-hari di Moravia dan Silesia akan menjadi campuran dari sisa-sisa dialek lokal tua, beberapa bentuk bahasa Ceko baku dan khususnya bahasa Ceko yang umum. Perbedaan yang paling menonjol adalah pergeseran dalam preposisi yang digunakan dan kasus kata benda, misalnya k jídlu (untuk makan - datif) (seperti bahasa Jerman - zum Essen) menjadi na jídlo (akusatif), seperti dalam bahasa Slowakia, na jedlo. Ini merupakan kesalahpahaman umum bahwa penggunaan bahasa Ceko standar di situasi sehari-hari lebih sering daripada di Bohemia. Bahasa Ceko Standar mulai dibakukan oleh kaum revivalis nasional Ceko pada abad ke-19, berdasarkan terjemahan yang sudah tiga ratus tahun dari Alkitab (Alkitab Kralice) menggunakan varian yang lebih tua dari bahasa saat ini (misalnya, lebih memilih -ý- menjadi -ej-). Bentuk-bentuk standar merupakan hal yang biasa dalam bahasa lisan baik di Moravia maupun di Silesia. Beberapa orang Moravia dan orang Silesia cenderung mengatakan bahwa mereka menggunakan bahasa yang "benar", tidak seperti rekan-rekan mereka orang-orang Bohemia.
Suatu kasus khusus adalah dialek Silesia Cieszyn, dituturkan di Silesia Cieszyn (Těšínsko) yang merupakan dialek transisi antara bahasa Ceko dan Polandia.
Beberapa dialek Moravia selatan juga kadang-kadang, meskipun jarang, dianggap (juga oleh ahli bahasa Ceko pada tahun 90-an atau setelahnya, misalnya Václav Machek dalam bukunya "Etymologický slovník jazyka českého", 1997 ISBN 80-7106-242-1, hal 8, yang berbicara tentang dialek "Moravia-Slovakia" dari wilayah Moravia "Slovácko") akan menjadi dialek nyata dari bahasa Slovakia yang berakar dalam kerajaan Moravia ketika orang Moravia dan orang Slowakia adalah satu bangsa (tanpa Bohemia) dengan satu bahasa. Dialek mereka masih memiliki akhiran yang sama (untuk kata benda dan kata ganti infleksi dan untuk verba terkonjugasi) sebagai bahasa Slowakia.
Dialek minoritas dituturkan di Daerah Plzeň dan bagian Barat Bohemia dan di bagian barat wilayah bekas Prachens yang belainan antara lain dengan intonasi pertanyaan: semua kata kecuali kata terakhir kalimat memiliki nada tinggi. Ini adalah alasan mengapa orang-orang dari Plzeň dikatakan "menyanyi". Kata-kata yang dimulai dengan pertanyaan sering diberi tambahan "-pa": "Kolipa je hodin?" (Ceko biasa: "Kolik je hodin?"; bahasa Indonesia: "Jam berapa sekarang?"). Kata-kata seperti "ini" (bahasa Ceko biasa: "tento / tato / toto") sering diganti dengan "tuten/Tuta/tuto"; beberapa contoh lainnya: "Apakah ini?" adalah "Copa to je?" dan "Apa yang terjadi?" adalah "Copa?" bukannya "Co je to?/Co se stalo?" atau "Mengapa?" adalah "Pročpa?" bukan "Proč?". Wilayah Chodsko merupakan rumah bagi dialek yang sangat khusus dari orang Chods yang mengungsi sekitar abad ke-10 dari Silesia berkat perlindungan perbatasan sebelah barat Bohemia.
Deklinasi
Bahasa Ceko biasanya mengacu pada kasus kata benda dengan angka dan mempelajarinya dengan menggunakan pertanyaan yang mereka adalah jawabannya. Angka-angka ini tidak selalu sesuai dengan nomor kasus dalam bahasa lain (misalnya, lokatif dan instrumental bahasa Slovenia dikenal sebagai kasus ke-5 dan ke-6). Ketika belajar kata baru, anak-anak Ceko melafalkan kasus dengan menggunakan satu set frasa contoh, yang ditampilkan sebagai berikut:

Kasus yang digunakan tergantung pada beberapa variabel.
Preposisi dengan Kasus-Kasus Tertentu
Aturan yang paling sederhana yang mengatur deklinasi nomina adalah penggunaan preposisi (předložky). Terkecuali ekspresi dan frasa umum, setiap preposisi disesuaikan dengan kasus deklinasi nomina tertentu, tergantung pada penggunaan. Berikut ini adalah contoh dasar dari preposisi umum dan kasus nomina yang berhubungan (Catatan: contoh ini hanya mewakili satu keadaan. Seringkali setiap preposisi dapat digunakan dengan dua atau lebih kasus nomina tergantung pada kalimat).
Faktor kedua yang memengaruhi deklinasi nomina adalah kata kerja yang digunakan. Dalam tata bahasa Ceko, kasus akusatif berfungsi sebagai objek langsung dan kasus datif berfungsi sebagai objek tak langsung. Beberapa verba memerlukan kasus genitif untuk digunakan.
Perhitungan dan Deklinasi
Faktor ketiga yang memengaruhi deklinasi nomina adalah angka. Bahasa Ceko memiliki sistem perhitungan Slavik yang khas, dijelaskan sebagai berikut dengan contoh maskulin yang menggerakkan nomina muž (manusia):
Bilangan memiliki pola deklinasi dalam bahasa Ceko. Nomor dua, misalnya sebagai berikut:

Angka-angka ini tunggal (jednotné číslo), jamak (množné číslo), dan tetap dual. Jumlah ganda hanya digunakan untuk bagian tertentu dari tubuh manusia: tangan, bahu, mata, telinga, lutut, kaki, dan payudara. Dalam semuanya kecuali dua dari bagian tubuh atas (mata dan telinga) nomor ganda hanya sisa dan memengaruhi aspek deklinasi sangat sedikit (kebanyakan kasus genitif dan preposisional). Namun, dalam bahasa Ceko umum akhiran ganda kasus instrumental ini digunakan sebagai bentuk jamak instrumental biasa, misalnya s kluky (dengan anak laki-laki) menjadi s klukama, dan seterusnya untuk semua kata benda.
Jenis Kelamin
Ketiga jenis kelamin adalah maskulin, feminin dan netral dengan maskulin dibagi lagi menjadi hidup dan tak hidup. Kata untuk individu dengan jenis kelamin biologis biasanya memiliki jenis kelamin tata bahasa yang sesuai dengan hanya beberapa pengecualian; sama antara kata benda maskulin, perbedaan antara hidup dan tak hidup juga mengikuti makna. Kata lain memiliki jenis kelamin tata bahasa yang sewenang-wenang. Jadi, misalnya, pes (anjing) itu maskulin bernyawa, stůl (meja) maskulin tak bernyawa, kočka (kucing) dan židle (kursi) adalah feminin, dan morče (hamster) dan světlo (cahaya) adalah netral.
Bentuk Kata Kerja
Dibandingkan dengan bahasa Inggris atau bahasa Rumania, bahasa Ceko memiliki seperangkat bentuk kalimat yang agak sederhana, yaitu bentuk waktu sekarang (simple present tense), bentuk waktu lampau (simple past tense) dan bentuk waktu akan datang (future tense).
Bentuk waktu lampau digunakan dalam hampir semua kasus tindakan masa lalu dan menggantikan setiap bentuk lampau dalam bahasa Inggris (past simple, past perfect dan dalam beberapa kasus present perfect). Bentuk lampau biasanya dibentuk dengan membubuhkan sebuah -l- di ujung kata kerja, kadang-kadang dengan perubahan (kurang signifikan) kata dasar yang kecil. Setelah menambahkan -l-, huruf ditambahkan agar sesuai dengan subjek (-a untuk feminin, -o untuk netral, -i, -y atau -a untuk jamak).
Keterangan waktu sekarang juga digunakan untuk menggambarkan tindakan-tindakan yang berkelanjutan yang terus saat ini, di mana dalam bahasa Inggris sebuah present perfect akan digunakan, misalnya, "I've been doing this for three hours". Dalam bahasa Ceko, karena tidak ada Present Perfect, Present Indicative digunakan dan secara langsung diterjemahkan sebagai "I do this for three hours". Namun, ketika Present Perfect ini digunakan untuk menunjukkan tindakan masa lalu tanpa referensi waktu (misalnya "Saya sudah berkunjung ke Italia tiga kali"), maka bentuk lampau akan digunakan.
Kadang-kadang ada juga bentuk kedua verba tertentu (seperti "pergi", "melakukan") yang menunjukkan tindakan kebiasaan atau tindakan berulang. Ini dikenal sebagai bentuk iteratif (berulang). Misalnya kata kerja jít ("pergi dengan menggunakan kaki/berjalan") memiliki bentuk berulang chodit ("pergi/berjalan secara rutin").
Konteks masa depan adalah bagian berubah-berubah lainnya dari tata bahasa Ceko. Kata kerja dalam bahasa Ceko dapat dibagi menjadi dua aspek yang mengungkapkan tindakan yang sedang berlangsung (aspek tdk sempurna) dan satu mengungkapkan hasil dari suatu tindakan (aspek perfektif). Kebanyakan kata kerja memiliki rekan-rekan yang berbeda di setiap aspek yang membentuk pasangan. Kata kerja perfektif hanya dapat mengekspresikan suatu tindakan yang sudah selesai (masa lalu) atau salah satu yang belum diselesaikan (masa depan), tetapi yang terakhir dinyatakan dalam bahasa Ceko menggunakan konteks masa sekarang. Dengan demikian, konteks masa depan (misalnya: budu psát untuk psát, menulis) hanya dapat digunakan untuk kata kerja tdk sempurna; namun, konteks masa sekarang dari napsat (pasangan perfektif dari psát juga menunjukkan tindakan di masa depan.
Pasangan aspektual pada umumnya ada dua jenis:
Alfabet Bahasa Ceko
Alfabet Ceko adalah versi abjad Latin yang digunakan ketika menulis dalam bahasa Ceko. Prinsip dasarnya adalah "satu suara, satu huruf" dan penambahan tanda diakritik di atas huruf untuk mewakili suara asing ke Latin. Alfabet dari beberapa bahasa Eropa Timur (Slavia, Baltik, tetapi juga lainnya, seperti Estonia) didasarkan pada alfabet Ceko, menghilangkan atau menambahkan karakter sesuai dengan kebutuhan mereka. Pengecualian yang paling penting adalah Bahasa Polandia yang mengembangkan naskah Romawi sendiri secara mandiri. Alfabet Ceko juga merupakan tulisan standar Akademija Nauk, digunakan ketika menyalin huruf Sirilik Slavia (Rusia, Ukraina, Bulgaria, Makedonia dan lain-lain).
Alfabet bahasa Ceko terdiri atas 42 grafem:
A, Á, B, C, Č, D, Ď, E, É, Ě, F, G, H, Ch, I, Í, J, K, L, M, N, Ň, O, Ó, P, Q, R, Ř, S, Š, T, Ť, U, Ú, Ů, V, W, X, Y, Ý, Z, Ž
Huruf Q dan W digunakan secara khusus dalam kata-kata asing dan dalam bahasa Ceko digantikan dengan Kv dan V sehingga menjadi kata "naturalisasi"; digraf dz dan dž juga digunakan sebagian besar untuk kata-kata asing dan tidak memiliki tempat terpisah dalam alfabet. Huruf-huruf dengan háček, čárka dan kroužek biasanya diperlakukan sebagai varian, maka pengecualian mereka dari alfabet standar.
KONTEN ISI
1. Nama
2. Fonologi
2.1. Huruf Vokal
2.2. Contoh Teks
2.3. Diftong
2.4. Konsonan
2.5. Penekanan
3. Sintaksis dan Morfologi
3.1. Susunan Kata
3.2. Jenis Kata
3.3. Dialek
3.4. Deklinasi
3.4.1. Preposisi dengan Kasus-Kasus Tertentu
3.4.2. Perhitungan dan Deklinasi
3.4.3. Jenis Kelamin
3.5. Bentuk Kata Kerja
4. Alfabet Bahasa Ceko
Nama
Nama "čeština", Ceko, berasal dari suku Slavia dari Ceko ("Čech", jamaknya "Češi" or "Čechové" (archaic)) yang menghuni Bohemia Tengah dan suku-suku Slavia tetangga bersatu di bawah pemerintahan dinasti Premyslid ("Přemyslovci"). Menurut legenda, bahasa Ceko berasal dari nenek moyang Čech, yang membawa suku orang Ceko ke dalam tanahnya. Nama varian bahasa Inggris "Bohemia" digunakan sampai akhir abad ke-19 yang mencerminkan nama bahasa Inggris asli dari negara Ceko yang berasal dari suku Celtic Boii yang mendiami wilayah itu sejak abad ke-4 SM.
Fonologi
Fonologi bahasa Ceko mungkin tampak tidak menarik bagi pembicara bahasa Inggris karena beberapa kata-kata tidak memiliki huruf hidup: zmrzl (padat beku), ztvrdl (mengeras), scvrkl (menyusut), čtvrthrst (seperempat genggaman), blb (bodoh), vlk (serigala) , atau smrt (kematian). Contoh populer dari hal tersebut adalah ungkapan ""strč prst skrz krk" yang berarti "tancapkan jari melalui tenggorokanmu" atau ungkapan "Smrž pln skvrn zvlhl z mlh." yang berarti "Morel penuh bintik-bintik yang dibasahi oleh kabut". Konsonan l dan r dapat berfungsi sebagai inti dari suku kata dalam bahasa Ceko karena mereka adalah konsonan sonoran. Fenomena yang sama juga terjadi dalam bahasa Inggris Amerika, di mana suku kata berkurang pada ujung "butter" dan "bottle" yang diucapkan [bʌɾ.ɹ] dan [bɒɾ.l], dengan suku kata konsonan sebagai inti suku kata. Bahasa Ceko juga memiliki fitur konsonan ř, fonem yang dikatakan unik untuk bahasa Ceko.
Huruf Vokal
Terdapat 10 huruf vokal dalam bahasa Ceko yang dianggap sebagai fonem individual. Ada 5 vokal pendek dan 5 vokal panjang.
Vokal panjang ditandai dengan aksen tajam di atas huruf atau tanda cincin di atas huruf.
/ iː / diwakili oleh huruf í dan ý
/ uː / diwakili oleh huruf ú dan ů
/ ɛː / diwakili oleh huruf é
/ aː / diwakili oleh huruf á
/ oː / diwakili oleh huruf ó
Vokal pendek
/ɪ/ diwakili oleh huruf i dan y
/u/ diwakili oleh huruf u
/ɛ/ diwakili oleh huruf e dan e
/a/ diwakili oleh huruf a
/o/ diwakili oleh huruf o
Contoh Teks
Bahasa Ceko: Všichni lidé se rodí svobodní a sobě rovní co do důstojnosti a práv. Jsou nadáni rozumem a svědomím a mají spolu jednat v duchu bratrství.
Bahasa Indonesia: Semua manusia dilahirkan bebas dan sama dalam martabat dan hak. Mereka dibekali dengan akal dan hati nurani dan harus bertindak dalam semangat persaudaraan.
Perhatikan bahwa ě bukan vokal terpisah. Sejalan dengan y, ý dan ů, itu adalah grafem yang dipelihara untuk alasan historis (lihat Ortografi Bahasa Ceko). ó hanya ada di kata-kata pinjaman.
Diftong
Ada tiga diftong dalam bahasa Ceko:
/aʊ̯/ diwakili oleh au (hampir seluruhnya dalam kata-kata asal luar negeri)
/eʊ̯/ diwakili oleh eu (dalam kata asal luar negeri saja)
/oʊ̯/ diwakili oleh ou
Ketika kelompok-kelompok ini datang bersama-sama pada batas morfem, mereka tidak membentuk diftong dalam standar bahasa Ceko, misalnya naučit, neučit, poučit ([-au-, -eu-, -ou-] or [-aʔu-, -eʔu-, -oʔu-]). Dalam kata asli bahasa Ceko, hanya ou yang ada sebagai diftong. Kelompok huruf hidup ia, ie, ii, io, dan iu dalam kata asing juga tidak dianggap sebagai diftong; mereka juga dapat diucapkan dengan /j/ antara huruf vokal [ɪja, ɪjɛ, ɪjɪ, ɪjo, ɪju].
Konsonan

Konsonan di dalam tanda kurung dianggap sebagai alofon dari konsonan lain:
[ŋ] adalah alofon dari /n/ ketika sebelumnya konsonan velar (/k/ dan /ɡ/).
[g] adalah alofon bersuara dari /k/ ketika mendahului konsonan disuarakan, kecuali dalam kata-kata
pinjaman.
[dz͡] adalah alofon dari /ts͡/ ketika mendahului konsonan bersuara.
Perhentian glotal (ʔ) yang muncul sebagai pemisah antara dua vokal atau kata awalnya sebelum vokal tidak dianggap sebagai fonem yang terpisah atau alofon dari satu.
/ʃ/ diwakili oleh huruf š
/ʒ/ diwakili oleh huruf ž
/ɲ/ diwakili oleh huruf ň
/c/ diwakili oleh huruf ť
/ɟ/ diwakili oleh huruf ď
/ɦ/ diwakili oleh huruf h
/x/ diwakili oleh digraf ch
/ts/ diwakili oleh huruf c
/tʃ/ diwakili oleh huruf č
/dʒ/ diwakili oleh digraf dž
/r̝/ diwakili oleh huruf ř
Konsonan lain diwakili oleh karakter yang sama (huruf) seperti dalam IPA/AFI.
Penekanan
Penekanan utama selalu tetap pada suku kata pertama dari unit yang ditekankan yang biasanya identik dengan kata. Pengecualiannya adalah:
- Preposisi monosilabel membentuk unit dengan kata-kata berikut (jika kata berikut ini tidak lebih dari tiga suku kata). Penekanan ditempatkan pada preposisi: misalnya Praha (Praha) → do Prahy (ke Praha).
- Beberapa kata monosilabel (misalnya "mi" (aku), "ti" ((untuk) kamu), "to" (kata ganti benda), "si/se" (diri sendiri), "jsem" (am dalam bahasa Inggris), "jsi" (are dalam bahasa Inggris)) adalah klitik — mereka tidak ditekankan dan membentuk unit dengan kata-kata sebelumnya. Sebuah klitik tidak bisa menjadi kata pertama dalam kalimat karena memerlukan kata sebelumnya untuk membentuk unit dengan kata selanjutnya. Contohnya: Napsal jsem ti ten dopis, aku telah menulis surat untukmu.
Penekanan dalam bahasa Ceko menunjukkan batas-batas antara kata-kata, tetapi tidak membedakan makna kata. Hal ini juga tidak memiliki pengaruh pada kualitas atau kuantitas huruf vokal. Huruf vokal tidak berkurang dalam suku kata tanpa tekanan dan kedua vokal panjang dan pendek dapat terjadi baik dalam suku kata bertekanan atau tanpa tekanan.
Sintaksis dan Morfologi
Seperti dalam bahasa Slavia kebanyakan, banyak kata (terutama kata benda, kata kerja dan kata sifat) memiliki banyak bentuk (infleksi). Dalam hal ini, bahasa Ceko dan bahasa-bahasa Slavia lebih dekat dengan asal Indo-Eropa mereka daripada bahasa lain dalam keluarga yang sama yang telah kehilangan banyak infleksi. Selain itu, dalam bahasa Ceko, aturan morfologi sangatlah tidak teratur dan banyak variasi bentuk resmi, sehari-hari dan kadang-kadang semi-resmi.
Susunan Kata
Susunan kata dalam bahasa Ceko berfungsi hampir sama dengan penekanan kalimat dan artikel dalam bahasa Inggris. Seringkali semua permutasi dari kata dalam klausa adalah mungkin. Sementara sebagian besar permutasi berbagi makna yang sama, mereka berbeda dalam artikulasi topik-fokus.
Misalnya: Češi udělali revoluci (Orang-orang Ceko membuat revolusi), Revoluci udělali Češi (Ini adalah orang-orang Ceko yang membuat revolusi) dan Češi revoluci udělali (Orang-orang Ceko memang membuat revolusi). Biasanya susunan kata mengikuti pola berdasarkan pentingnya kata-kata dinyatakan - dari paling tidak penting sampai yang paling penting. Dengan mengatakan Revoluci udělali Češi pembicara menekankan bahwa itu adalah orang Ceko dan bukan misalnya Jerman atau Slowakia yang membuat revolusi. Dengan mengatakan Češi revoluci udělali, pembicara menekankan bahwa revolusi telah dilakukan, dan yang menjadi jauh lebih penting dari itu adalah orang Ceko yang berdiri di belakangnya. Dikombinasikan dengan melodi suara kalimat yang adalah sama untuk setiap jenis kalimat - pengumuman, pertanyaan dan keharusan dan yang menandai akhir setiap kalimat, orang dapat dengan mudah memahami konteks penting dari apa yang dikatakan dengan hanya mendengarkan kata akhir dalam setiap kalimat.
Jenis Kata
- Nomina (podstatné jméno)
- Adjektiva (přídavné jméno)
- Pronomina (zájmeno)
- Bilangan (číslovka)
- Verba (sloveso)
- Adverbia (příslovce)
- Preposisi (předložka)
- Konjungsi (spojka)
- Partikel (částice)
- Kata seru (citoslovce)
- Adjektiva (přídavné jméno)
Dialek
Di Republik Ceko, dua varian yang berbeda atau interdialek dari pengucapan bahasa Ceko dapat ditemukan, keduanya lebih terkait atau kurang untuk wilayah geografis di dalam negeri. Yang pertama dan paling banyak digunakan adalah "bahasa Ceko Umum", diucapkan terutama di Bohemia. Ia memiliki beberapa perbedaan tata bahasa dari bahasa Ceko "baku" disertai dengan beberapa perbedaan dalam pengucapan. Perubahan pengucapan paling umum adalah -y menjadi-e dalam beberapa keadaan, -é menjadi-ý- dalam beberapa keadaan (-ej- di lainnya). Selain itu, deklinasi kata benda akan berubah, terutama kasus instrumental. Daripada memiliki berbagai akhiran (tergantung pada jenis kelamin) dalam instrumental, Bohemia hanya akan menempatkan -ama atau -ma pada akhir dari semua deklinasi instrumental yang jamak. Saat ini, bentuk-bentuk ini sangat umum di seluruh Republik Ceko, termasuk Moravia dan Silesia. Selain itu, pengucapan berubah sedikit, seperti Bohemia cenderung memiliki huruf vokal lebih terbuka daripada Moravia. Hal ini konon sangat lazim di kalangan orang-orang dari Praha.
Varian utama kedua diucapkan di Moravia dan Silesia. Saat ini. varian tersebut sangat dekat dengan bentuk Bohemia Ceko yang umum. Varian ini memiliki beberapa kata yang berbeda dari kesetaraan bahasa Ceko yang baku. Sebagai contoh dalam dialek lisan di Brno, tramvaj (trem) adalah šalina (berasal dari bahasa Jerman "ElektriSCHELINIE"). Tidak seperti di Bohemia, Moravia dan Silesia cenderung memiliki dialek yang lebih lokal yang memvariasikan dari tempat ke tempat, namun seperti halnya di Bohemia, sebagian besar telah sudah sangat dipengaruhi dan sebagian besar digantikan oleh bahasa Ceko yang umum. Bentuk lisan sehari-hari di Moravia dan Silesia akan menjadi campuran dari sisa-sisa dialek lokal tua, beberapa bentuk bahasa Ceko baku dan khususnya bahasa Ceko yang umum. Perbedaan yang paling menonjol adalah pergeseran dalam preposisi yang digunakan dan kasus kata benda, misalnya k jídlu (untuk makan - datif) (seperti bahasa Jerman - zum Essen) menjadi na jídlo (akusatif), seperti dalam bahasa Slowakia, na jedlo. Ini merupakan kesalahpahaman umum bahwa penggunaan bahasa Ceko standar di situasi sehari-hari lebih sering daripada di Bohemia. Bahasa Ceko Standar mulai dibakukan oleh kaum revivalis nasional Ceko pada abad ke-19, berdasarkan terjemahan yang sudah tiga ratus tahun dari Alkitab (Alkitab Kralice) menggunakan varian yang lebih tua dari bahasa saat ini (misalnya, lebih memilih -ý- menjadi -ej-). Bentuk-bentuk standar merupakan hal yang biasa dalam bahasa lisan baik di Moravia maupun di Silesia. Beberapa orang Moravia dan orang Silesia cenderung mengatakan bahwa mereka menggunakan bahasa yang "benar", tidak seperti rekan-rekan mereka orang-orang Bohemia.
Suatu kasus khusus adalah dialek Silesia Cieszyn, dituturkan di Silesia Cieszyn (Těšínsko) yang merupakan dialek transisi antara bahasa Ceko dan Polandia.
Beberapa dialek Moravia selatan juga kadang-kadang, meskipun jarang, dianggap (juga oleh ahli bahasa Ceko pada tahun 90-an atau setelahnya, misalnya Václav Machek dalam bukunya "Etymologický slovník jazyka českého", 1997 ISBN 80-7106-242-1, hal 8, yang berbicara tentang dialek "Moravia-Slovakia" dari wilayah Moravia "Slovácko") akan menjadi dialek nyata dari bahasa Slovakia yang berakar dalam kerajaan Moravia ketika orang Moravia dan orang Slowakia adalah satu bangsa (tanpa Bohemia) dengan satu bahasa. Dialek mereka masih memiliki akhiran yang sama (untuk kata benda dan kata ganti infleksi dan untuk verba terkonjugasi) sebagai bahasa Slowakia.
Dialek minoritas dituturkan di Daerah Plzeň dan bagian Barat Bohemia dan di bagian barat wilayah bekas Prachens yang belainan antara lain dengan intonasi pertanyaan: semua kata kecuali kata terakhir kalimat memiliki nada tinggi. Ini adalah alasan mengapa orang-orang dari Plzeň dikatakan "menyanyi". Kata-kata yang dimulai dengan pertanyaan sering diberi tambahan "-pa": "Kolipa je hodin?" (Ceko biasa: "Kolik je hodin?"; bahasa Indonesia: "Jam berapa sekarang?"). Kata-kata seperti "ini" (bahasa Ceko biasa: "tento / tato / toto") sering diganti dengan "tuten/Tuta/tuto"; beberapa contoh lainnya: "Apakah ini?" adalah "Copa to je?" dan "Apa yang terjadi?" adalah "Copa?" bukannya "Co je to?/Co se stalo?" atau "Mengapa?" adalah "Pročpa?" bukan "Proč?". Wilayah Chodsko merupakan rumah bagi dialek yang sangat khusus dari orang Chods yang mengungsi sekitar abad ke-10 dari Silesia berkat perlindungan perbatasan sebelah barat Bohemia.
Deklinasi
Bahasa Ceko biasanya mengacu pada kasus kata benda dengan angka dan mempelajarinya dengan menggunakan pertanyaan yang mereka adalah jawabannya. Angka-angka ini tidak selalu sesuai dengan nomor kasus dalam bahasa lain (misalnya, lokatif dan instrumental bahasa Slovenia dikenal sebagai kasus ke-5 dan ke-6). Ketika belajar kata baru, anak-anak Ceko melafalkan kasus dengan menggunakan satu set frasa contoh, yang ditampilkan sebagai berikut:

Kasus yang digunakan tergantung pada beberapa variabel.
Preposisi dengan Kasus-Kasus Tertentu
Aturan yang paling sederhana yang mengatur deklinasi nomina adalah penggunaan preposisi (předložky). Terkecuali ekspresi dan frasa umum, setiap preposisi disesuaikan dengan kasus deklinasi nomina tertentu, tergantung pada penggunaan. Berikut ini adalah contoh dasar dari preposisi umum dan kasus nomina yang berhubungan (Catatan: contoh ini hanya mewakili satu keadaan. Seringkali setiap preposisi dapat digunakan dengan dua atau lebih kasus nomina tergantung pada kalimat).
- Genitif: během (selama), podle/dle (berdasarkan/bersama dengan), vedle (di samping), kolem (sekitar), okolo (sekitar), do (ke), od(e) (dari), z(e) (dari), bez(e) (tanpa), místo (bukan), u (di).
- Datif: k(e) (terhadap), proti (terhadap), díky (terima kasih kepada), naproti (berlawanan).
- Akusatif: skrz(e) (melewati), pro (untuk), na (untuk).
- Lokatif: o (tentang), na (di atas), při (ke dalam, di, sekitar), v (di), po (di atas).
- Instrumental: za (di belakang), před (di depan), mezi (di antara), pod(e) (di bawah), s(e) (dengan), nad(e) (di atas).
- Datif: k(e) (terhadap), proti (terhadap), díky (terima kasih kepada), naproti (berlawanan).
Faktor kedua yang memengaruhi deklinasi nomina adalah kata kerja yang digunakan. Dalam tata bahasa Ceko, kasus akusatif berfungsi sebagai objek langsung dan kasus datif berfungsi sebagai objek tak langsung. Beberapa verba memerlukan kasus genitif untuk digunakan.
Perhitungan dan Deklinasi
Faktor ketiga yang memengaruhi deklinasi nomina adalah angka. Bahasa Ceko memiliki sistem perhitungan Slavik yang khas, dijelaskan sebagai berikut dengan contoh maskulin yang menggerakkan nomina muž (manusia):
- Untuk nomor satu, jumlah tunggal digunakan: jeden muž.
- Untuk nomor 2, 3, dan 4, kasus apapun dapat digunakan, tergantung pada fungsi dari kata benda dalam kalimat: dva muži (nominatif). "Vidím dva muže" (akusatif).
- Untuk semua nomor dari 5, pada jamak genitif digunakan ketika kata benda biasanya akan berada dalam kasus nominatif, akusatif atau vokatif: pet mužů. "Pět mužů je tam." Lima orang laki-laki di sana. "Vidím pět mužů." Aku melihat lima orang laki-laki. Untuk kasus lain, bagaimanapun, kata benda tidak ditempatkan di genitif. "Nad pěti muži." Di atas lima orang laki-laki (instrumental).
- Untuk nomor 2, 3, dan 4, kasus apapun dapat digunakan, tergantung pada fungsi dari kata benda dalam kalimat: dva muži (nominatif). "Vidím dva muže" (akusatif).
Bilangan memiliki pola deklinasi dalam bahasa Ceko. Nomor dua, misalnya sebagai berikut:

Angka-angka ini tunggal (jednotné číslo), jamak (množné číslo), dan tetap dual. Jumlah ganda hanya digunakan untuk bagian tertentu dari tubuh manusia: tangan, bahu, mata, telinga, lutut, kaki, dan payudara. Dalam semuanya kecuali dua dari bagian tubuh atas (mata dan telinga) nomor ganda hanya sisa dan memengaruhi aspek deklinasi sangat sedikit (kebanyakan kasus genitif dan preposisional). Namun, dalam bahasa Ceko umum akhiran ganda kasus instrumental ini digunakan sebagai bentuk jamak instrumental biasa, misalnya s kluky (dengan anak laki-laki) menjadi s klukama, dan seterusnya untuk semua kata benda.
Jenis Kelamin
Ketiga jenis kelamin adalah maskulin, feminin dan netral dengan maskulin dibagi lagi menjadi hidup dan tak hidup. Kata untuk individu dengan jenis kelamin biologis biasanya memiliki jenis kelamin tata bahasa yang sesuai dengan hanya beberapa pengecualian; sama antara kata benda maskulin, perbedaan antara hidup dan tak hidup juga mengikuti makna. Kata lain memiliki jenis kelamin tata bahasa yang sewenang-wenang. Jadi, misalnya, pes (anjing) itu maskulin bernyawa, stůl (meja) maskulin tak bernyawa, kočka (kucing) dan židle (kursi) adalah feminin, dan morče (hamster) dan světlo (cahaya) adalah netral.
Bentuk Kata Kerja
Dibandingkan dengan bahasa Inggris atau bahasa Rumania, bahasa Ceko memiliki seperangkat bentuk kalimat yang agak sederhana, yaitu bentuk waktu sekarang (simple present tense), bentuk waktu lampau (simple past tense) dan bentuk waktu akan datang (future tense).
Bentuk waktu lampau digunakan dalam hampir semua kasus tindakan masa lalu dan menggantikan setiap bentuk lampau dalam bahasa Inggris (past simple, past perfect dan dalam beberapa kasus present perfect). Bentuk lampau biasanya dibentuk dengan membubuhkan sebuah -l- di ujung kata kerja, kadang-kadang dengan perubahan (kurang signifikan) kata dasar yang kecil. Setelah menambahkan -l-, huruf ditambahkan agar sesuai dengan subjek (-a untuk feminin, -o untuk netral, -i, -y atau -a untuk jamak).
Keterangan waktu sekarang juga digunakan untuk menggambarkan tindakan-tindakan yang berkelanjutan yang terus saat ini, di mana dalam bahasa Inggris sebuah present perfect akan digunakan, misalnya, "I've been doing this for three hours". Dalam bahasa Ceko, karena tidak ada Present Perfect, Present Indicative digunakan dan secara langsung diterjemahkan sebagai "I do this for three hours". Namun, ketika Present Perfect ini digunakan untuk menunjukkan tindakan masa lalu tanpa referensi waktu (misalnya "Saya sudah berkunjung ke Italia tiga kali"), maka bentuk lampau akan digunakan.
Kadang-kadang ada juga bentuk kedua verba tertentu (seperti "pergi", "melakukan") yang menunjukkan tindakan kebiasaan atau tindakan berulang. Ini dikenal sebagai bentuk iteratif (berulang). Misalnya kata kerja jít ("pergi dengan menggunakan kaki/berjalan") memiliki bentuk berulang chodit ("pergi/berjalan secara rutin").
Konteks masa depan adalah bagian berubah-berubah lainnya dari tata bahasa Ceko. Kata kerja dalam bahasa Ceko dapat dibagi menjadi dua aspek yang mengungkapkan tindakan yang sedang berlangsung (aspek tdk sempurna) dan satu mengungkapkan hasil dari suatu tindakan (aspek perfektif). Kebanyakan kata kerja memiliki rekan-rekan yang berbeda di setiap aspek yang membentuk pasangan. Kata kerja perfektif hanya dapat mengekspresikan suatu tindakan yang sudah selesai (masa lalu) atau salah satu yang belum diselesaikan (masa depan), tetapi yang terakhir dinyatakan dalam bahasa Ceko menggunakan konteks masa sekarang. Dengan demikian, konteks masa depan (misalnya: budu psát untuk psát, menulis) hanya dapat digunakan untuk kata kerja tdk sempurna; namun, konteks masa sekarang dari napsat (pasangan perfektif dari psát juga menunjukkan tindakan di masa depan.
Pasangan aspektual pada umumnya ada dua jenis:
- perfektif diperoleh dengan memberi awalan imperfektif dengan preposisi, misalnya psát menjadi napsat;
- Bentuknya berbeda dalam akhiran, misalnya dát (perfektif) menjadi dávat (imperfektif) atau koupit (perfektif) menjadi kupovat (imperfektif).
Alfabet Bahasa Ceko
Alfabet Ceko adalah versi abjad Latin yang digunakan ketika menulis dalam bahasa Ceko. Prinsip dasarnya adalah "satu suara, satu huruf" dan penambahan tanda diakritik di atas huruf untuk mewakili suara asing ke Latin. Alfabet dari beberapa bahasa Eropa Timur (Slavia, Baltik, tetapi juga lainnya, seperti Estonia) didasarkan pada alfabet Ceko, menghilangkan atau menambahkan karakter sesuai dengan kebutuhan mereka. Pengecualian yang paling penting adalah Bahasa Polandia yang mengembangkan naskah Romawi sendiri secara mandiri. Alfabet Ceko juga merupakan tulisan standar Akademija Nauk, digunakan ketika menyalin huruf Sirilik Slavia (Rusia, Ukraina, Bulgaria, Makedonia dan lain-lain).
Alfabet bahasa Ceko terdiri atas 42 grafem:
A, Á, B, C, Č, D, Ď, E, É, Ě, F, G, H, Ch, I, Í, J, K, L, M, N, Ň, O, Ó, P, Q, R, Ř, S, Š, T, Ť, U, Ú, Ů, V, W, X, Y, Ý, Z, Ž
Huruf Q dan W digunakan secara khusus dalam kata-kata asing dan dalam bahasa Ceko digantikan dengan Kv dan V sehingga menjadi kata "naturalisasi"; digraf dz dan dž juga digunakan sebagian besar untuk kata-kata asing dan tidak memiliki tempat terpisah dalam alfabet. Huruf-huruf dengan háček, čárka dan kroužek biasanya diperlakukan sebagai varian, maka pengecualian mereka dari alfabet standar.
Senin, 27 Juni 2011
BAHASA TELUGU (తెలుగు)
Bahasa Telugu adalah bahasa utama yang dituturkan di negara bagian Andhra Pradesh dan distrik Yanam, di mana bahasa tersebut merupakan bahasa resminya. Bahasa ini juga dituturkan di negara-negara bagian tetangga, seperti Chattisgarh, Karnataka, Maharashtra, Orissa dan Tamil Nadu, itu merupakan bahasa dengan jumlah penutur asli terbesar ketiga di India (74 juta pada tahun 2001) dan ketiga belas dalam daftar bahasa yang sering dituturkan di seluruh dunia.
Konten Isi
1. Etimologi
2. Fonologi
3. Alfabet
4. Tata Bahasa
5. Kosa Kata
6. Sistem Penulisan
7. Contoh percakapan bahasa Telugu
Etimologi
Etimologi bahasa Telugu tidak diketahui secara pasti. Bahasa ini diperkirakan telah diturunkan dari trilingga, seperti pada Trilingga Desa, "Negara dari Tiga Lingga". Menurut legenda Hindu, Syiwa turun sebagai lingga di tiga gunung, yaitu Kaleswara, Srisaila dan Brimeswara yang menandai batas-batas negara Telugu.
Trilingga Desa membentuk batas-batas tradisional wilayah Telugu. Telugu juga dikenal sebagai "Tenungu", "Tenugu" dan "Telungu" yang semuanya dipopulerkan oleh Nannayya dan Tikkana.
Fonologi
Bahasa Telugu adalah satu-satunya bahasa di India yang memiliki semua kata yang berakhiran dengan suara vokal. Telugu disebut "Italia Timur" oleh penjelajah Italia, Niccolò Da Conti. Dia menciptakan istilah tersebut pada abad 15 ketika mengunjungi Kekaisaran Wijayanagara pada masa pemerintahan Vira Vijaya Bukka Raya di tahun 1520-an.
Seperti bahasa Turki, bahasa Hungaria, dan bahasa Finlandia, kata-kata dalam bahasa Telugu juga memiliki huruf vokal dalam akhiran infleksional yang diselaraskan dengan vokal suku kata sebelumnya.
Bahasa Telugu menampilkan bentuk harmoni vokal dimana vokal kedua di nomina bersuku dua dan akar kata sifat akan mengubah apakah vokal pertama bersifat tegang atau kendur. Jika vokal kedua adalah vokal terbuka (yaitu: /aː/ or /a/), maka vokal pertama akan lebih terbuka dan terpusat (misalnya [mɛːka] 'kambing', berlawanan dengan [meːku] 'kuku').
Alfabet
Onamaalu atau alfababet bahasa Telugu terdiri atas 60 simbol, yaitu 16 huruf vokal, 3 pengubah vokal dan 41 huruf konsonan. Alfabet Telugu dan Sanskerta adalah serupa dan menunjukkan korespondensi satu-satu. Bahasa Telugu memiliki set huruf-huruf yang mengikuti sistem ilmiah untuk mengekspresikan suara. Hal ini sangat mendukung untuk fonetik. Bahasa Telugu memiliki lebih banyak huruf daripada bahasa India. Beberapa dari mereka diperkenalkan untuk mengekspresikan nuansa halus dari perbedaan dalam suara.
Bahasa Telugu memiliki tanda Nol-penuh atau anusvāra ( ం ), Nol-setengah atau arthanusvāra atau Chandrabindu ( ఁ) dan Visarga untuk menyampaikan berbagai nuansa suara hidung. la dan La, ra dan Ra dibedakan.
Bahasa telugu memiliki .CH dan .JH yang tidak direpresentasikan dalam bahasa Sansekerta, dan S, SH, dan KSH yang tidak ditemukan dalam bahasa Tamil.
Tulisan Telugu dapat memperbanyak berbagai macam fonetik bahasa Sansekerta tanpa kehilangan orisinalitas teks itu. Telugu telah membuat huruf yang ekspresif semua suara dan karena itu harus berurusan dengan pinjaman yang signifikan dari bahasa Sansekerta, Tamil dan Hindustan.
Huruf Vokal
అ (A)
ఆ (AA/Ā)
ఇ (I)
ఈ (II/Ī)
ఉ (U)
ఊ (UU/Ū)
ఋ (R vokal)
ౠ (RR vokal)
ఌ (L vokal)
ౡ (LL vokal)
ఎ (E)
ఏ (EE/Ē)
ఐ (AI)
ఒ (O)
ఓ (OO/Ō)
ఔ (AU)
అం (AṀ)
అః (AḤ)
Huruf Konsonan

Sistem Penomoran
Bahasa Telugu memiliki sistem penomoran tersendiri yaitu seperti berikut.

Tata Bahasa
Aturan tata bahasa Telugu klasik secara keseluruhan disebut Vyākaraṇaṁ (వ్యాకరణం).
Risalah pertama pada tata bahasa Telugu, "Andhra Sabda Chintamani" ditulis dalam bahasa Sanskerta oleh Nannayya, yang dianggap sebagai penyair dan penerjemah bahasa Telugu pertama pada abad 11 Masehi. Tata bahasa ini mengikuti pola yang ada dalam risalah tata bahasa, seperti Aṣṭādhyāyī dan Vālmīkivyākaranam, tapi tidak seperti Panini, Nannayya membagi karyanya menjadi lima bab, meliputi samjnā, sandhi, ajanta, halanta dan kriya. Setiap aturan tata bahasa Telugu berasal dari konsep-konsep Pāṇinian.
Pada abad ke-19, Chinnaya Suri menulis sebuah karya sederhana pada tata bahasa Telugu yang disebut "Bala Vyākaranam" dengan meminjam konsep dan ide dari tata bahasa Nannayya.
Subjek-Objek-Verba
Urutan kalimat pada bahasa Telugu adalah SOV (Subjek-Objek-Verba):

Kalimat tersebut juga dapat diartikan "Ramudu akan pergi ke sekolah", tergantung pada konteks kalimat. Tetapi itu tidak memengaruhi urutan SOV.
Infleksi/Perubahan Suara
Tidak seperti bahasa Dravida lainnya, bahasa Telugu adalah bahasa infleksi, kata benda bahasa Telugu yang mengalami perubahan suara adalah nomor/bilangan (tunggal, jamak), jenis kelamin (maskulin, feminin, netral) dan kasus (akusatif, nominatif, genitif, datif, vokatif, instrumental dan lokatif).
Jenis Kelamin
Bahasa Telugu memiliki tiga jenis kelamin, yaitu maskulin, feminin dan netral.
Pronomina/Kata Ganti
Pronomina bahasa Telugu mencakup kata ganti orang (orang yang berbicara, orang berbicara kepada atau orang-orang atau hal-hal yang dibicarakan). Pronomina tak terbatas, kata ganti relatif (menghubungkan bagian-bagian kalimat) dan kata ganti timbal balik atau refleksif (di mana objek dari suatu kata kerja sedang bertindak dengan subjek verba itu).
Bahasa Telugu menggunakan bentuk yang sama untuk jenis kelamin feminin tunggal dan netral-kata ganti orang ketiga (అది/ad̪ɪ) digunakan untuk merujuk pada hewan dan benda.
Kosakata
Bahasa Telugu menggabungkan persentase yang tinggi dari kata-kata Bahasa Sanskerta dan Bahasa Inggris. Pada tingkat yang lebih rendah, bahasa Telugu juga berisi kata-kata bahasa Arab dan Farsi, seperti "maidanamu" (maydan dalam bahasa Arab), "kalamu" (qalam dalam Bahasa Arab) dan "bazaar" (kata asli Persia). Saat ini bahasa Telugu diklasifikasikan sebagai bahasa Dravida yang ditandai dengan kehadiran yang signifikan kata-kata pinjaman dari bahasa Sanskerta.
Kosakata bahasa Telugu, khususnya di wilayah Telangana memiliki koleksi pinjaman kata bahasa Arab-Farsi yang telah dimodifikasi agar sesuai dengan fonologi bahasa Telugu. Hal ini disebabkan oleh pemerintahan Muslim berabad-abad di wilayah ini, seperti kerajaan-kerajaan bekas Golkonda dan Hyderabad. (misalnya: కబురు, /kaburu/ untuk bahasa Urdu dari /xabar/, خبر atau జవాబు, /dʒavaːbu/ untuk bahasa Urdu dari /dʒawɑːb/, جواب).
Kosakata bahasa Telugu modern dapat dikatakan membentuk diglosia karena versi formal dan standar bahasa sangat dipengaruhi oleh bahasa Sanskerta yang juga diajarkan di sekolah-sekolah dan digunakan oleh pemerintah dan lembaga-lembaga agama Hindu. Namun, bahasa Telugu sehari-hari bervariasi tergantung pada wilayah dan status sosial.
Sistem Penulisan
 Nama Telugu ditulis
Nama Telugu ditulis
dalam huruf Telugu
Sejarawan muslim terkenal dan cendekiawan abad 10, Al-Biruni mengacukan bahasa dan naskah bahasa Telugu sebagai "Andhri".
Naskah bahasa Telugu ditulis dari kiri ke kanan dan terdiri atas urutan karakter sederhana dan/atau kompleks. Skripnya adalah suku kata di alam-unit dasar penulisan suku kata. Karena jumlah suku kata yang mungkin sangat besar, suku katanya terdiri atas lebih unit dasar, seperti huruf vokal (“achchu” atau “swaram”) dan huruf konsonan (“hallu” atau “vyanjanam”). Konsonan dalam gugus konsonan mengambil bentuk yang sangat berbeda dari bentuk yang mereka ambil di tempat lain. Konsonan yang dianggap murni ialah tanpa suara vokal di dalamnya. Namun, itu sangat tradisional untuk menulis dan membaca konsonan dengan suara huruf vokal "a" yang tersirat. Ketika konsonan digabungkan dengan tanda-tanda vokal lain, bagian vokal ditunjukkan secara ortografi menggunakan tanda-tanda vokal yang dikenal sebagai "maatras". Bentuk vokal "maatras" juga sangat berbeda dari bentuk vokal yang sepadan.
Pola keseluruhan terdiri atas enam puluh simbol, yang 16 adalah vokal, tiga pengubah vokal, dan empat puluh satu konsonan. Spasi digunakan sebagai pemisah antarkata-kata.
Kalimat dalam bahasa Telugu diakhiri oleh garis tegak tunggal | ("purna viramam") atau garis tegak ganda || ("deergha viramam"). Secara tradisional, dalam tulisan tangan, kata-kata bahasa Telugu tidak dipisahkan oleh spasi. Tanda baca modern (koma, titik koma, dll.) diperkenalkan dengan munculnya cetakan.
Ada satu set simbol untuk angka, meskipun angka Arab biasanya digunakan.
bahasa Telugu diberikan poin kode Unicode: 0C00-0C7F (3072-3199).
Contoh Percakapan Bahasa Telugu
హాయ్, మీ పేరు ఏమిటి? (Hāy, mī pēru ēmiṭi?/hai, siapa namamu?)
నా పేరు . . . ఉంది. (Nā pēru . . . undi./Namaku . . . .)
మీరు ఎక్కడ నివసిస్తున్నారు? (Mīru ekkaḍa nivasistunnāru?/Dimana kamu tinggal?)
మీరు ఎక్కడ నుండి ఉన్నాయి? (Mīru ekkaḍa nuṇḍi unnāyi?/Darimana kamu berasal?)
నేను ఇండోనేషియా నుండి వస్తాయి. (Nēnu iṇḍōnēṣiyā nuṇḍi vastāyi./Saya berasal dari Indonesia.)
ఉదయం మంచి! (Udayaṁ man̄ci!/Selamat pagi!)
మధ్యాహ్నం మంచి! (Madhyāhnaṁ man̄ci!/Selamat siang!)
సాయంత్రం మంచి! (Sāyantraṁ man̄ci!/Selamat sore!)
రాత్రి మంచి! (Rātri man̄ci!/Selamat malam!)
పుట్టినరోజు శుభాకాంక్షలు! (Puṭṭinarōju śubhākāṅkṣalu!/Selamat ulang tahun!)
Konten Isi
1. Etimologi
2. Fonologi
3. Alfabet
4. Tata Bahasa
5. Kosa Kata
6. Sistem Penulisan
7. Contoh percakapan bahasa Telugu
Etimologi
Etimologi bahasa Telugu tidak diketahui secara pasti. Bahasa ini diperkirakan telah diturunkan dari trilingga, seperti pada Trilingga Desa, "Negara dari Tiga Lingga". Menurut legenda Hindu, Syiwa turun sebagai lingga di tiga gunung, yaitu Kaleswara, Srisaila dan Brimeswara yang menandai batas-batas negara Telugu.
Trilingga Desa membentuk batas-batas tradisional wilayah Telugu. Telugu juga dikenal sebagai "Tenungu", "Tenugu" dan "Telungu" yang semuanya dipopulerkan oleh Nannayya dan Tikkana.
Fonologi
Bahasa Telugu adalah satu-satunya bahasa di India yang memiliki semua kata yang berakhiran dengan suara vokal. Telugu disebut "Italia Timur" oleh penjelajah Italia, Niccolò Da Conti. Dia menciptakan istilah tersebut pada abad 15 ketika mengunjungi Kekaisaran Wijayanagara pada masa pemerintahan Vira Vijaya Bukka Raya di tahun 1520-an.
Seperti bahasa Turki, bahasa Hungaria, dan bahasa Finlandia, kata-kata dalam bahasa Telugu juga memiliki huruf vokal dalam akhiran infleksional yang diselaraskan dengan vokal suku kata sebelumnya.
Bahasa Telugu menampilkan bentuk harmoni vokal dimana vokal kedua di nomina bersuku dua dan akar kata sifat akan mengubah apakah vokal pertama bersifat tegang atau kendur. Jika vokal kedua adalah vokal terbuka (yaitu: /aː/ or /a/), maka vokal pertama akan lebih terbuka dan terpusat (misalnya [mɛːka] 'kambing', berlawanan dengan [meːku] 'kuku').
Alfabet
Onamaalu atau alfababet bahasa Telugu terdiri atas 60 simbol, yaitu 16 huruf vokal, 3 pengubah vokal dan 41 huruf konsonan. Alfabet Telugu dan Sanskerta adalah serupa dan menunjukkan korespondensi satu-satu. Bahasa Telugu memiliki set huruf-huruf yang mengikuti sistem ilmiah untuk mengekspresikan suara. Hal ini sangat mendukung untuk fonetik. Bahasa Telugu memiliki lebih banyak huruf daripada bahasa India. Beberapa dari mereka diperkenalkan untuk mengekspresikan nuansa halus dari perbedaan dalam suara.
Bahasa Telugu memiliki tanda Nol-penuh atau anusvāra ( ం ), Nol-setengah atau arthanusvāra atau Chandrabindu ( ఁ) dan Visarga untuk menyampaikan berbagai nuansa suara hidung. la dan La, ra dan Ra dibedakan.
Bahasa telugu memiliki .CH dan .JH yang tidak direpresentasikan dalam bahasa Sansekerta, dan S, SH, dan KSH yang tidak ditemukan dalam bahasa Tamil.
Tulisan Telugu dapat memperbanyak berbagai macam fonetik bahasa Sansekerta tanpa kehilangan orisinalitas teks itu. Telugu telah membuat huruf yang ekspresif semua suara dan karena itu harus berurusan dengan pinjaman yang signifikan dari bahasa Sansekerta, Tamil dan Hindustan.
Huruf Vokal
అ (A)
ఆ (AA/Ā)
ఇ (I)
ఈ (II/Ī)
ఉ (U)
ఊ (UU/Ū)
ఋ (R vokal)
ౠ (RR vokal)
ఌ (L vokal)
ౡ (LL vokal)
ఎ (E)
ఏ (EE/Ē)
ఐ (AI)
ఒ (O)
ఓ (OO/Ō)
ఔ (AU)
అం (AṀ)
అః (AḤ)
Huruf Konsonan

Sistem Penomoran
Bahasa Telugu memiliki sistem penomoran tersendiri yaitu seperti berikut.

Tata Bahasa
Aturan tata bahasa Telugu klasik secara keseluruhan disebut Vyākaraṇaṁ (వ్యాకరణం).
Risalah pertama pada tata bahasa Telugu, "Andhra Sabda Chintamani" ditulis dalam bahasa Sanskerta oleh Nannayya, yang dianggap sebagai penyair dan penerjemah bahasa Telugu pertama pada abad 11 Masehi. Tata bahasa ini mengikuti pola yang ada dalam risalah tata bahasa, seperti Aṣṭādhyāyī dan Vālmīkivyākaranam, tapi tidak seperti Panini, Nannayya membagi karyanya menjadi lima bab, meliputi samjnā, sandhi, ajanta, halanta dan kriya. Setiap aturan tata bahasa Telugu berasal dari konsep-konsep Pāṇinian.
Pada abad ke-19, Chinnaya Suri menulis sebuah karya sederhana pada tata bahasa Telugu yang disebut "Bala Vyākaranam" dengan meminjam konsep dan ide dari tata bahasa Nannayya.
Subjek-Objek-Verba
Urutan kalimat pada bahasa Telugu adalah SOV (Subjek-Objek-Verba):

Kalimat tersebut juga dapat diartikan "Ramudu akan pergi ke sekolah", tergantung pada konteks kalimat. Tetapi itu tidak memengaruhi urutan SOV.
Infleksi/Perubahan Suara
Tidak seperti bahasa Dravida lainnya, bahasa Telugu adalah bahasa infleksi, kata benda bahasa Telugu yang mengalami perubahan suara adalah nomor/bilangan (tunggal, jamak), jenis kelamin (maskulin, feminin, netral) dan kasus (akusatif, nominatif, genitif, datif, vokatif, instrumental dan lokatif).
Jenis Kelamin
Bahasa Telugu memiliki tiga jenis kelamin, yaitu maskulin, feminin dan netral.
Pronomina/Kata Ganti
Pronomina bahasa Telugu mencakup kata ganti orang (orang yang berbicara, orang berbicara kepada atau orang-orang atau hal-hal yang dibicarakan). Pronomina tak terbatas, kata ganti relatif (menghubungkan bagian-bagian kalimat) dan kata ganti timbal balik atau refleksif (di mana objek dari suatu kata kerja sedang bertindak dengan subjek verba itu).
Bahasa Telugu menggunakan bentuk yang sama untuk jenis kelamin feminin tunggal dan netral-kata ganti orang ketiga (అది/ad̪ɪ) digunakan untuk merujuk pada hewan dan benda.
Kosakata
Bahasa Telugu menggabungkan persentase yang tinggi dari kata-kata Bahasa Sanskerta dan Bahasa Inggris. Pada tingkat yang lebih rendah, bahasa Telugu juga berisi kata-kata bahasa Arab dan Farsi, seperti "maidanamu" (maydan dalam bahasa Arab), "kalamu" (qalam dalam Bahasa Arab) dan "bazaar" (kata asli Persia). Saat ini bahasa Telugu diklasifikasikan sebagai bahasa Dravida yang ditandai dengan kehadiran yang signifikan kata-kata pinjaman dari bahasa Sanskerta.
Kosakata bahasa Telugu, khususnya di wilayah Telangana memiliki koleksi pinjaman kata bahasa Arab-Farsi yang telah dimodifikasi agar sesuai dengan fonologi bahasa Telugu. Hal ini disebabkan oleh pemerintahan Muslim berabad-abad di wilayah ini, seperti kerajaan-kerajaan bekas Golkonda dan Hyderabad. (misalnya: కబురు, /kaburu/ untuk bahasa Urdu dari /xabar/, خبر atau జవాబు, /dʒavaːbu/ untuk bahasa Urdu dari /dʒawɑːb/, جواب).
Kosakata bahasa Telugu modern dapat dikatakan membentuk diglosia karena versi formal dan standar bahasa sangat dipengaruhi oleh bahasa Sanskerta yang juga diajarkan di sekolah-sekolah dan digunakan oleh pemerintah dan lembaga-lembaga agama Hindu. Namun, bahasa Telugu sehari-hari bervariasi tergantung pada wilayah dan status sosial.
Sistem Penulisan
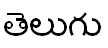 Nama Telugu ditulis
Nama Telugu ditulisdalam huruf Telugu
Sejarawan muslim terkenal dan cendekiawan abad 10, Al-Biruni mengacukan bahasa dan naskah bahasa Telugu sebagai "Andhri".
Naskah bahasa Telugu ditulis dari kiri ke kanan dan terdiri atas urutan karakter sederhana dan/atau kompleks. Skripnya adalah suku kata di alam-unit dasar penulisan suku kata. Karena jumlah suku kata yang mungkin sangat besar, suku katanya terdiri atas lebih unit dasar, seperti huruf vokal (“achchu” atau “swaram”) dan huruf konsonan (“hallu” atau “vyanjanam”). Konsonan dalam gugus konsonan mengambil bentuk yang sangat berbeda dari bentuk yang mereka ambil di tempat lain. Konsonan yang dianggap murni ialah tanpa suara vokal di dalamnya. Namun, itu sangat tradisional untuk menulis dan membaca konsonan dengan suara huruf vokal "a" yang tersirat. Ketika konsonan digabungkan dengan tanda-tanda vokal lain, bagian vokal ditunjukkan secara ortografi menggunakan tanda-tanda vokal yang dikenal sebagai "maatras". Bentuk vokal "maatras" juga sangat berbeda dari bentuk vokal yang sepadan.
Pola keseluruhan terdiri atas enam puluh simbol, yang 16 adalah vokal, tiga pengubah vokal, dan empat puluh satu konsonan. Spasi digunakan sebagai pemisah antarkata-kata.
Kalimat dalam bahasa Telugu diakhiri oleh garis tegak tunggal | ("purna viramam") atau garis tegak ganda || ("deergha viramam"). Secara tradisional, dalam tulisan tangan, kata-kata bahasa Telugu tidak dipisahkan oleh spasi. Tanda baca modern (koma, titik koma, dll.) diperkenalkan dengan munculnya cetakan.
Ada satu set simbol untuk angka, meskipun angka Arab biasanya digunakan.
bahasa Telugu diberikan poin kode Unicode: 0C00-0C7F (3072-3199).
Contoh Percakapan Bahasa Telugu
హాయ్, మీ పేరు ఏమిటి? (Hāy, mī pēru ēmiṭi?/hai, siapa namamu?)
నా పేరు . . . ఉంది. (Nā pēru . . . undi./Namaku . . . .)
మీరు ఎక్కడ నివసిస్తున్నారు? (Mīru ekkaḍa nivasistunnāru?/Dimana kamu tinggal?)
మీరు ఎక్కడ నుండి ఉన్నాయి? (Mīru ekkaḍa nuṇḍi unnāyi?/Darimana kamu berasal?)
నేను ఇండోనేషియా నుండి వస్తాయి. (Nēnu iṇḍōnēṣiyā nuṇḍi vastāyi./Saya berasal dari Indonesia.)
ఉదయం మంచి! (Udayaṁ man̄ci!/Selamat pagi!)
మధ్యాహ్నం మంచి! (Madhyāhnaṁ man̄ci!/Selamat siang!)
సాయంత్రం మంచి! (Sāyantraṁ man̄ci!/Selamat sore!)
రాత్రి మంచి! (Rātri man̄ci!/Selamat malam!)
పుట్టినరోజు శుభాకాంక్షలు! (Puṭṭinarōju śubhākāṅkṣalu!/Selamat ulang tahun!)
Minggu, 26 Juni 2011
ISTILAH KOMPUTER DAN INTERNET DALAM BAHASA INDONESIA
Di era globalisasi ini, semua pasti mengenal komputer dan internet. Komputer dan internet adalah sesuatu yang tidak pernah lepas dari kehidupan kita. Komputer dan internet memiliki istilah-istilah tersendiri yang semuanya berasal dari bahasa Inggris. Tetapi, beberapa negara di Eropa telah membuat kata-kata atau istilah-istilah yang berpadanan dengan istilah-istilah komputer dan internet dalam bahasa Inggris tersebut. Bahasa Indonesia sebenarnya juga telah mempunyai padanan yang memiliki arti yang sama dengan istilah komputer dan internet berbahasa Inggris tersebut. Berikut adalah istilah komputer dan internet yang telah tersedia padanan katanya dalam bahasa Indonesia.
Sumber: http://id.wikipedia.org/ dan http://pusatbahasa.kemdiknas.go.id/glosarium/
Istilah Asing | Istilah Bahasa Indonesia |
7-layer reference model abend recovery program abnormal ending (abend) abort about absolute address absolute error abstract class accelerated graphic port (AGP) accelerator board accelerator cards accelerator chart accelerator program acceptance test acceptance testing acceptor access access address access arm access channel access code access code file access control access control list access control matrix access controls directories access cycle access delay access file access level file access method access network access permission access protocol access right access scheme access time account account executive accounting information system (AIS) accounting machines accounting plus accounting software accounting systems and knowledge base accumulator accuracy document acknowledge character acknowledgment active file active window add-ons address address book adventure game adware American Standard Code For Information Interchange (ASCII) amplifier ancestor file antivirus program application file archival file attachment attachment file bandwidth bookmark bookmarks broadband browse browser browsing bulletin board buffer buffering cache carbon copy/cc cellular telephone chat chatting software close collaborative software collision communication channel communication satellite communication software compact disk computer device computer software computer worm computer-aided software engineering (CASE) connect connection cookie copy copyright cordless mouse crash Ctrl/End custom software cut cyberspace database datasource data warehouse defaults delete/del desktop publishing software detailed design document device device driver dial-up modem display device disk buffer domain download edit electronic software distribution end user end-user computing ergonomic mouse folder forward/fwd freeware geosynchronous satellite Global Positioning System (GPS) graphic software groupware hack hacker hacking hardware home homepage hosting HTML files input device interference intranet install installation interface internet service provider keyboard keyword knowledge base knowledge worker lag LCD monitor LED printer light-emitting diode link liquid crystal display (LCD) load local area network (LAN) login logout mailing list mainboard menu bar microsatellite modem monitor mouse multi-user network networking networking software new page newsgroup offline online optical mouse optomechanical mouse output device pager passphrase password paste peripheral device platform pointing device port preview printer processor proxy server public domain (PD) public domain software random access memory (RAM) satellite satellite footprint save scan scanner scanning setting server share/sharing sign in sign out sign up site software AG software development software engineering software maintenance software metric software packages software piracy software quality software reliability spreadsheet statistical software storage device surfing system software telesoftware uniform Resource Identifier (URI) Uniform Resource Locator (URL) universal serial bus (USB) update upload user user friendly user group user interface user interface design user manual user mode username utility software virtual reality virus scanner web browser webpage website wide area network (WAN) wideband window window close wireless wireless communication wireless computing wireless LAN wireless modem world wide web worm | model referensi 7 lapis program pemulihan aben pengakhiran abnormal gugurkan ikhwal, tentang alamat mutlak galat mutlak kelas abstrak porta grafik terakselerasi (PGA) papan akselerator kartu akselerator bagan akselerator program akselerator uji penerimaan pengujian penerimaan penerima akses alamat akses tangan akses, lengan akses kanal akses, saluran akses kode akses berkas kode akses kendali akses daftar kendali akses matriks kendali akses direktori kendali akses siklus akses tundaan akses; tunda akses berkas akses berkas aras akses metode akses jaringan akses izin akses protokol akses hak akses skema akses waktu akses akun eksekutif akun sistem informasi akuntansi (SAI) mesin akuntansi akuntansi plus perangkat lunak akuntansi sistem akuntansi dan basis pengetahuan akumulator dokumen akurasi karakter balasan salam balas berkas aktif jendela aktif pengaya, pasang tambah alamat buku alamat permainan pengembaraan perangkat lunak beriklan Kode Standar Amerika untuk Pertukaran Informasi (KSAPI) penguat berkas terdahulu, berkas moyang program antivirus berkas aplikasi berkas pengarsipan lampiran berkas lampiran lebar pita menandai, tandai penanda, marka buku pita lebar jelajahi, ramban penjelajah, peramban menjelajahi, meramban, penjelajahan papan buletin penyangga penyanggaan tembolok tembusan ponsel obrol, mengobrol, rumpi peranti lunak obrolan tutup peranti lunak kolaboratif tabrakan, bertabrakan saluran komunikasi, kanal komunikasi satelit komunikasi perangkat lunak komunikasi cakram padat, piringan cakram perangkat komputer perangkat lunak komputer cacing komputer rekayasa perangkat lunak berbantuan komputer (RPLBK) menyambung, menghubungkan, mengoneksi koneksi, sambungan kuki salin, kopi, menyalin, mengopi, salinan, kopian hak cipta tetikus nirkabel tabrakan data Kontrol(Ktrl)/Selesai (Sls) perangkat lunak tersuai potong, memotong dunia maya basis data sumber data gudang data standar, baku hapus, menghapus perangkat lunak penerbitan desktop dokumen desain terinci perangkat penggerak perangkat modem panggilan/dial-up perangkat tampilan penyangga cakram/diska ranah unduh, ambil data, muat turun sunting, ubah surel, ratel, imel, surat-e, posel distribusi perangkat lunak elektronik pengguna akhir komputasi pengguna akhir tetikus ergonomis folder, map, pelipat terusan perangkat gratis satelit geosinkron Sistem Kedudukan Sejagat (SKS) perangkat lunak grafis perangkat kelompok meretas peretas, perusak sistem peretasan perangkat keras beranda laman, beranda hosting, tuan rumah berkas Bahasa Marka Hiperteks (BMHT) peranti masukan gangguan (sinyal) intranet pasang, instalasi, memasang, menginstalasi instalasi, pemasangan antarmuka penyedia jasa internet (PJI) papan tombol kata kunci basis pengetahuan pekerja pengetahuan lambat monitor TKC pencetak DC diode cahaya tautan, pautan, pranala tampilan kristal cair muat, memuat jaringan wilayah setempat (JWS/JAS) log masuk, masuk log keluar, keluar milis, forum ratel, daftar alamat papan induk bilah menu mikrosatelit modem monitor tetikus multipengguna jaringan jejaring perangkat lunak jaringan halaman baru kelompok warta, kelompok diskusi luring (luar jaringan), terputus, tidak terhubung daring (dalam jaringan), tersambung, terhubung tetikus optik tetikus optomekanik perangkat keluaran pejer, penyeranta frasa sandi, kalimat sandi kata sandi tempel, rekat, menempel, merekatkan perangkat periferal/pinggiran pelantar peranti penunjuk porta pratayang, pratonton, pratinjau, pratilik cetak, mencetak pencetak prosesor, pemroses peladen proksi ranah publik (RP) perangkat lunak ranah publik memori akses acak (MAA) satelit jejak satelit simpan pindai, memindai pemindai pindaian pengaturan juru sita, peladen berbagi masuk keluar daftar, mendaftar situs, tapak perangkat lunak AG pengembangan perangkat lunak rekayasa perangkat lunak (RPL) pemeliharaan perangkat lunak metrik perangkat lunak paket perangkat lunak pembajakan perangkat lunak kualitas perangkat lunak keandalan perangkat lunak lembar kerja perangkat lunak statistik perangkat penyimpanan berselancar, selancar maya perangkat lunak sistem teleperangkat lunak Pengenalpasti Sumber Daya Seragam (PPSDS) Pelokasi Sumber Daya Seragam (PSDS) Bus Beruntut Semesta (BBS) memperbarui, perbaruan, pemutakhiran, terkini unggah, mengunggah, mengirim data, memuat naik pengguna mudah digunakan, akrab dalam penggunaan kelompok penggunak antarmuka pengguna desain antarmuka pengguna panduan pengguna modus pengguna nama pengguna perangkat lunak utilitas realitas maya pemindai virus peramban ramatraya halaman ramatraya, laman ramatraya situs ramatraya jaringan wilayah luas (JWL/JAL) pita lebar jendela tutup jendela nirkabel komunikasi nirkabel komputasi nirkabel JWS/JAS nirkabel modem nirkabel waring wera wanua (WWW) cacing |
Sumber: http://id.wikipedia.org/ dan http://pusatbahasa.kemdiknas.go.id/glosarium/
Rabu, 01 Juni 2011
KUIS KATA BAKU FLASH
Akhirnya selesai juga pembuatan kuis berbentuk flash yang isinya tentang Kata Baku... Kalau mau mengunduh langsung klik tautan di bawah...
http://www.ziddu.com/download/15206744/quiz.swf.html
http://www.ziddu.com/download/15206744/quiz.swf.html
Langganan:
Komentar (Atom)


